HTTP Scaling for In-Cluster Traffic (Kubernetes Service)
This guide demonstrates how to scale applications based on cluster-internal HTTP traffic. These applications do not expose external Ingress resources, relying instead on Kubernetes Services for traffic routing. You’ll deploy a sample application, a matching Services, and a KEDA ScaledObject, and see how Kedify uses its proxy to manage traffic and enable efficient, load-based scaling — including scale-to-zero when there’s no demand.
To properly enable autoscaling with Kedify, network traffic needs to be automatically rewired by its autowiring feature, which manages Kubernetes Endpoints for specified Services, as detailed in the traffic autowire documentation.
Configuring service as the trafficAutowire option excludes setting any other trafficAutowire options because it effectively replaces all of them. Therefore, kedify-agent will wire the traffic by managing Kubernetes Endpoints belonging to the Services defined in service and fallbackService in the trigger metadata.
This type of traffic autowiring brings two more requirements on the application and autoscaling manifests:
- ScaledObject must define
fallbackService: because the kedify-agent uses it for injecting Endpoints to theservicedefined in the trigger metadata and kedify-proxy for routing. - Application service must NOT have selector defined: the Kubernetes control plane manages Endpoints for Services with selectors, which would collide with autowire feature. The
servicedefined in the trigger metadata must be without selector while thefallbackServiceshould carry the original selector you’d define on theserviceif it wasn’t autowired.
- A running Kubernetes cluster (a local cluster or cloud-based EKS, GKS, etc).
- The
kubectlcommand line utility installed and accessible. - Connect your cluster in the Kedify Dashboard.
- If you do not have a connected cluster, you can find more information in the installation documentation.
Deploy the following application to your cluster:
kubectl apply -f application.yamlThe whole application YAML:
apiVersion: apps/v1kind: Deploymentmetadata: name: applicationspec: replicas: 1 selector: matchLabels: app: application template: metadata: labels: app: application spec: containers: - name: application image: ghcr.io/kedify/sample-http-server:latest imagePullPolicy: Always ports: - name: http containerPort: 8080 protocol: TCP env: - name: RESPONSE_DELAY value: '0.3'---apiVersion: v1kind: Servicemetadata: name: application-servicespec: ports: - name: http protocol: TCP port: 8080 targetPort: http type: ClusterIP---apiVersion: v1kind: Servicemetadata: name: application-service-fallbackspec: ports: - name: http protocol: TCP port: 8080 targetPort: http type: ClusterIP selector: app: applicationDeployment(application-service): This defines the application itself. It’s a simple Go-based HTTP server designed for Kubernetes. It listens for HTTP requests, responds (with a configurable delay via theRESPONSE_DELAYenvironment variable), and exposes metrics.Service(application-service): This is the primary internal access point for the application within the cluster. Clients within the cluster target this Service’sClusterIPand port8080to reach the application.- When used with Kedify’s
trafficAutowire: servicefeature (configured in theScaledObjectbelow), thisServiceintentionally lacks a selector. Instead of Kubernetes automatically populating itsEndpointswith Pod IPs, the kedify-agent takes control. - It dynamically updates the
Endpointsfor thisServiceto point either to the kedify-proxy (when the scaler is active and healthy) or to the application-service-fallbackService(when the scaler is inactive or unhealthy). This allows Kedify to intercept traffic for metric collection and scaling purposes.
- When used with Kedify’s
Service(application-service-fallback): This is a standard Kubernetes Service that does use a selector (app: application-service) to directly target the applicationPodsmanaged by theDeployment.- It acts as a direct pathway to the application, bypassing the
kedify-proxy. - The kedify-agent uses this
Service'sendpoint information to populate the main application-service’sEndpointswhen the Kedify trigger enters a fallback state (e.g., due to metric collection issues) or when scaling is inactive. This ensures application availability even if the Kedify scaling mechanism encounters problems.
- It acts as a direct pathway to the application, bypassing the
Step 2: Apply ScaledObject to Autoscale and Autowire
Section titled “Step 2: Apply ScaledObject to Autoscale and Autowire”Apply the following ScaledObject:
kubectl apply -f scaledobject.yamlThe whole ScaledObject YAML:
kind: ScaledObjectapiVersion: keda.sh/v1alpha1metadata: name: applicationspec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: application cooldownPeriod: 5 minReplicaCount: 1 maxReplicaCount: 1 fallback: failureThreshold: 2 replicas: 1 advanced: restoreToOriginalReplicaCount: true horizontalPodAutoscalerConfig: behavior: scaleDown: stabilizationWindowSeconds: 5 triggers: - type: kedify-http metadata: hosts: application.keda service: application-service port: '8080' scalingMetric: requestRate targetValue: '1000' granularity: 1s window: 10s trafficAutowire: service fallbackService: application-service-fallbacktype(kedify-http): Specifies the use of the Kedify HTTP scaler, which monitors HTTP traffic.metadata.hosts(application-service.keda): The scaler monitors traffic directed to this hostname.metadata.service(application-service): The Kubernetes Service name associated with the traffic path being monitored and whose Endpoints will be managed.metadata.port(8080): The port on the specified service to monitor.metadata.scalingMetric(requestRate): The metric used for scaling decisions is the rate of incoming requests.metadata.targetValue(1000): Target value for the scaling metric; KEDA scales out when traffic meets or exceeds this value.metadata.granularity(1s): The time unit for the targetValue (i.e., requests per second).metadata.window(10s): Granularity at which the request rate is measured.metadata.trafficAutowire(service): This enables Kedify’s service autowiring feature.metadata.fallbackService(application-service-fallback): This specifies the name of the Service (application-service-fallback) that kedify-agent should point the main application-serviceEndpointsto when the kedify-http trigger is inactive, in a fallback state (due to errors), or scaling down to zero (if minReplicas allowed it).
You should see the ScaledObject in the Kedify Dashboard:
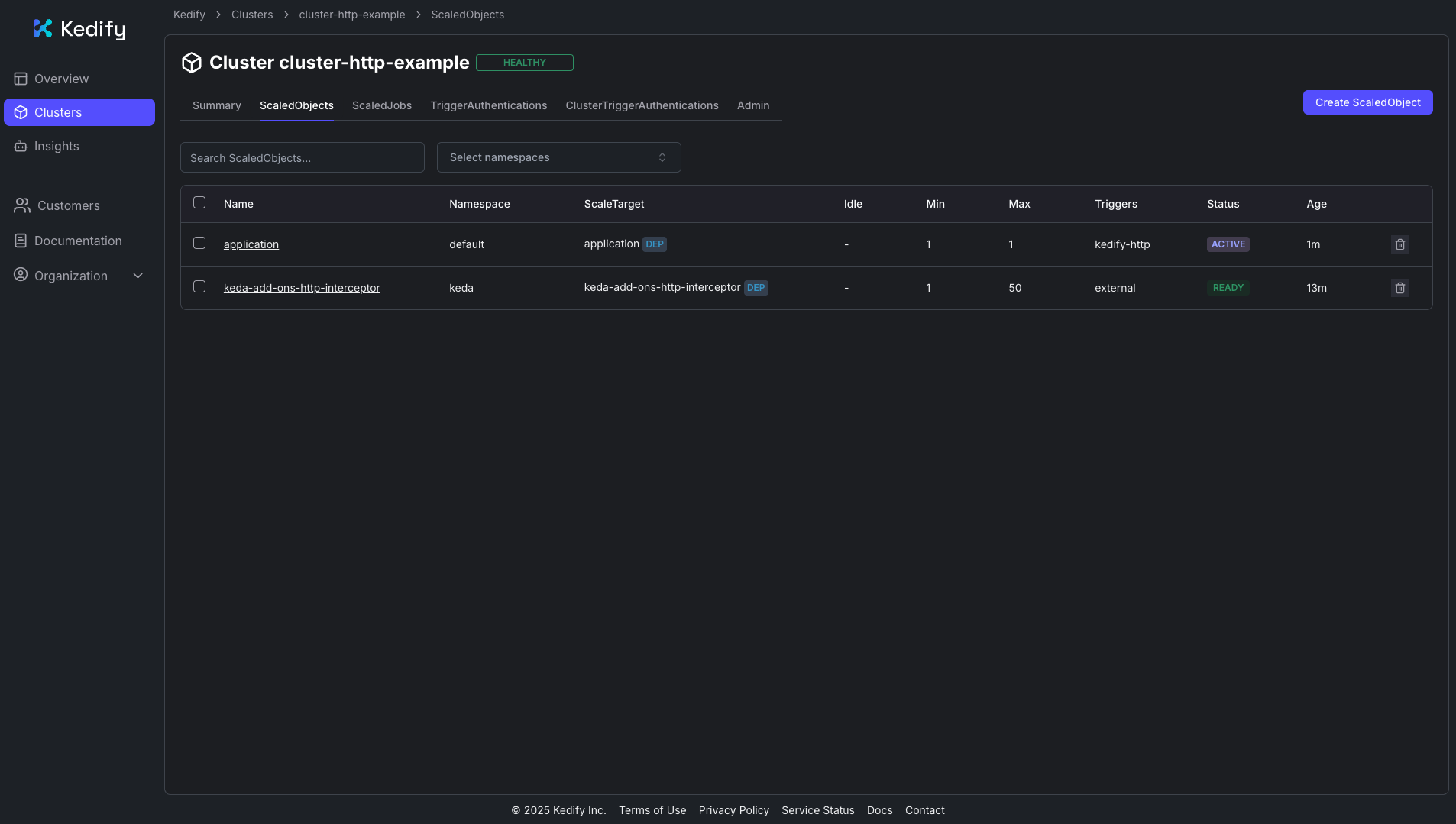
First, let’s test that the application responds to the requests. Because this application is not exposed outside of the cluster, you can spin up a curl pod internally to easily use the Kubernetes cluster DNS. Because the ScaledObject has configured hosts: application.keda in the metadata, you will need to tell curl to add a matching host HTTP header to the request too.
Deploy curl pod in the cluster:
kubectl run curl --image=curlimages/curl:latest --restart=Never --command -- /bin/sh -c "sleep infinity"Once the pod is ready execute curl command:
kubectl exec -it curl -- curl -I -H 'host: application.keda' http://application-service.default.svc.cluster.local:8080If everything is working, you should see the following output in your terminal:
HTTP/1.1 200 OKcontent-type: text/htmldate: Wed, 16 Apr 2025 11:32:30 GMTcontent-length: 320x-envoy-upstream-service-time: 302server: envoyNow, we can test higher load, we will deploy another pod with hey load testing tool:
kubectl run hey --image=ghcr.io/kedacore/tests-hey:latest --restart=Never --command -- /bin/sh -c "sleep infinity"Once it is ready, we will open a session in that pod:
kubectl exec -it hey -- shAnd finally execute the hey commands:
./hey -n 10000 -c 150 -host "application.keda" http://application-service.default.svc.cluster.local:8080After a while, you will see a response time histogram in the terminal:
Response time histogram: 0.300 [1] | 0.317 [8760] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 0.334 [962] |■■■■ 0.350 [27] | 0.367 [0] | 0.383 [0] | 0.400 [8] | 0.417 [44] | 0.433 [86] | 0.450 [3] | 0.467 [9] |
In the Kedify Dashboard, you can also see the load:

## Next steps
You can check the whole documentation of [HTTP Scaler](/documentation/scalers/http-scaler).