Cracking Bottlenecks: How KEDA Outsmarts Kubernetes Horizontal Pod Autoscaler

by Sharad Regoti
October 30, 2023
Kubernetes has become the de facto standard for deploying microservices, owing to its autoscaling and self-healing capabilities. By default, Kubernetes employs two components for autoscaling:
- Horizontal Pod Autoscaler (HPA): Dynamically adjusts the number of pod instances based on CPU and RAM metrics, ensuring optimal resource utilization.
- Vertical Pod Autoscaler (VPA): Automatically adjusts individual pod resource requests based on CPU and RAM usage patterns, optimizing pod resource allocations.
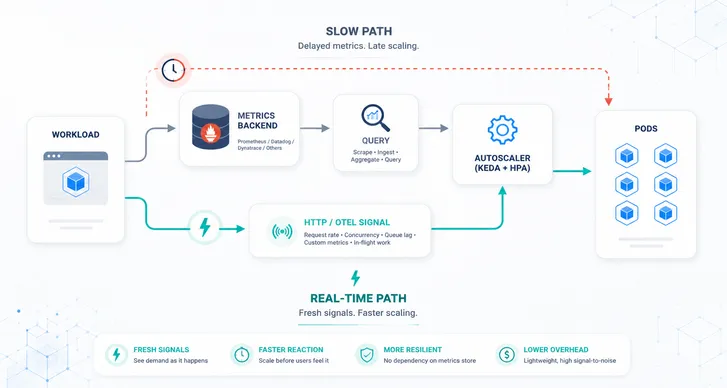
Using HPA or VPA is a great starting point and works well for applications under uniform load. However, in today’s cloud-native ecosystem, scaling solely on CPU and memory utilization against dynamic traffic patterns and fluctuating workloads is inadequate. This is where native autoscaling features of Kubernetes fall short.
For accommodating such unpredictable behavior we require systems that can adjust in real-time. This is where KEDA comes in. In this blog post, we will explore how KEDA overcomes the limitations of HPA and provides a user-friendly interface for diverse autoscaling needs.
Scaling Challenges of HPA
Consider an image processing application where users upload images via a mobile app interface. To meet the defined Service Level Agreement (SLA) of processing images within 30 seconds, the application’s processing time is directly influenced by the size of the image being processed. To optimize this, the upload API intelligently segregates incoming images based on their sizes and routes them to specific Kafka queues tailored for each size category. Each queue is serviced by specialized processing jobs equipped with algorithms designed for efficient image processing within the 30-second SLA.
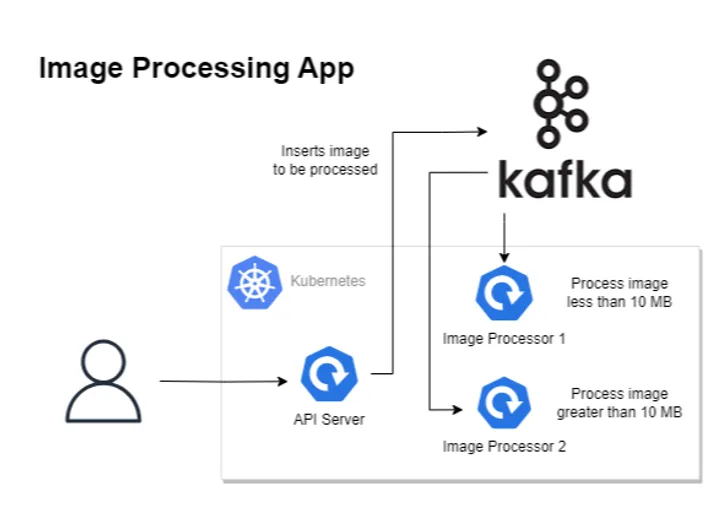
In this scenario, relying solely on CPU and RAM metrics for scaling would be insufficient and potentially detrimental to our SLA. Traditional metrics like CPU and RAM do not account for the intricacies of image processing times, which heavily depend on the image size and complexity of the algorithms used. Scaling based on Kafka queue size, which directly correlates with the volume and complexity of the images in the processing pipeline, ensures a responsive scaling strategy. By dynamically scaling based on the size of the image queues, the application can adhere to the 30-second processing SLA.
Custom Metrics and HPA
But by default, HPA can only make scaling decisions based on CPU and RAM metrics, as these are the only metrics available on the Metrics Server![]() . HPA can make decisions based on custom metrics, provided the custom metrics are available on the metrics server. However, the default implementation of the metric server only collects CPU and RAM information from the cluster.
. HPA can make decisions based on custom metrics, provided the custom metrics are available on the metrics server. However, the default implementation of the metric server only collects CPU and RAM information from the cluster.
To solve our use case in which we want HPA to scale based on Kafka queue size, we need to generate custom metrics such that HPA is able to scale based on them. This can be achieved by creating a Custom Metrics Server![]() that implements the Metrics API. However, implementing a custom metric server uncovers a series of complexities and challenges.
that implements the Metrics API. However, implementing a custom metric server uncovers a series of complexities and challenges.
Difficulties of Extending HPA using Custom Metrics Server
Creating custom metrics for HPA is no walk in the park. It demands intricate knowledge of Kubernetes internals, requiring developers to delve deep into interfaces and intricate code modifications. Below is a brief outline of the steps involved:
- Complex Implementation Details: Create a provider responsible for handling API requests for metrics. You must choose an appropriate provider interface: either CustomMetricsProvider or ExternalMetricsProvider, depending on your specific requirements.
- For our use case, we need to utilize CustomMetricsProvider.
- Implement the above interface by writing custom logic for individual metrics you want to add. This also includes handling authentication and authorization with multiple external entities.
- Create an API server to serve the metrics provided by your provider.
- Manage complex Kubernetes resources for deployment and provide credentials for connecting with external entities in a secure way.
- Limited Specificity and Continuous Updates: Extending HPA through a custom metrics server is inherently limited to one specific metric at a time. Each new metric necessitates a fresh implementation, leading to a continuous cycle of updates and modifications to the existing adapter.
- Cluster Restrictions and Conflicts: Kubernetes imposes a strict rule, only one Custom Metrics extension is allowed per cluster. This limitation poses significant challenges, especially in shared or diverse environments. If a tool like Prometheus Adapter or a DataDog adapter is already in use, attempting to integrate a custom adapter tailored for auto scaling becomes complex.
- Maintenance Overheads: Maintaining a custom metrics server comes with its own set of challenges. Developers have to maintain an additional component alongside their applications. This additional complexity leads to operational headaches in the long run.
Given these complexities, the path toward flexible autoscaling solutions in Kubernetes takes a significant turn. Instead of navigating the labyrinth of custom metrics servers and their associated challenges, a more elegant solution would be to use KEDA.
In the following sections, we will explore how KEDA overcomes these limitations and provides a seamless, user-friendly approach to autoscaling that aligns with the dynamic demands of modern cloud-native applications.
What is KEDA & How does it overcome HPA problems?
KEDA, which stands for Kubernetes Event-Driven Autoscaler, enables the scaling of pods based on external event sources. This allows Kubernetes applications to scale dynamically in response to events such as:
- Message Queues: Applications might need to scale based on the number of messages in a queue (like RabbitMQ or Kafka). If there’s a surge of unprocessed messages, it might be an indicator to scale up.
- Database Triggers: Changes or updates in a database (like a sudden increase in rows of a particular table) might necessitate an application scale-up to process or analyze the influx of data.
- External Webhooks: Incoming webhooks from third-party services (e.g., GitHub pushes or eCommerce transaction events) could require more resources to handle the additional load.
The above examples are just the tip of the iceberg. KEDA supports more than 60+ predefined event sources (scalers)![]() . To consume these event sources, KEDA provides a user-friendly interface that uses Kubernetes CRDs. Unlike the complexities of custom metrics servers, KEDA streamlines this process through a well-thought-out architecture.
. To consume these event sources, KEDA provides a user-friendly interface that uses Kubernetes CRDs. Unlike the complexities of custom metrics servers, KEDA streamlines this process through a well-thought-out architecture.
Understanding KEDA’s Architecture
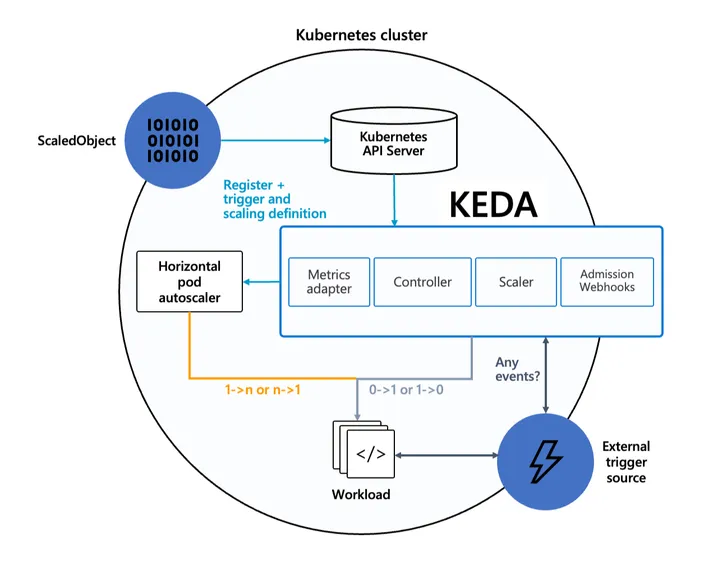
At its core, KEDA comprises three key components:
- KEDA Operator: A multifaceted entity comprising two essential components:
- Controller: Manages & acts on KEDA Custom Resource Definitions (CRDs).
- Scaler: Establishes connections to various event sources & fetches metrics.
- Metrics Server: Implements the Kubernetes Custom Metrics API and acts as an “adapter” to translate metrics obtained by querying KEDA operator (scaler) to a form that the Horizontal Pod Autoscaler can understand and consume to drive the autoscaling.
- Admission Webhooks: Automatically validate resource changes to prevent misconfiguration and enforce best practices using an admission controller.
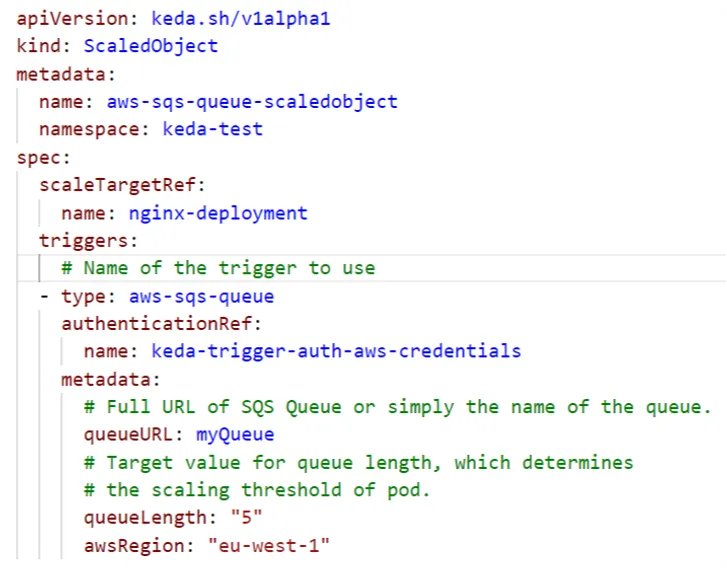
Scaled Objects & Scaled Jobs
KEDA introduces the concept of ScaledObjects and ScaledJobs in Kubernetes, which are custom resources that allow users to define how their workloads should scale based on specific events. Apart from defining scaling conditions, these CRDs offer fine-grained control over autoscaling behaviors. Here is an example of scaling an Nginx deployment based on AWS SQS queue size.
KEDA doesn’t stop at just overcoming the limitations of HPA; it goes above and beyond, offering functionalities that redefine auto scaling.
KEDA’s Exclusive Auto Scaling Features
- Scale Down to Zero: When there are no pending events or metrics triggering the workload, KEDA can automatically scale down the application to zero, reducing resource consumption to a minimum.
- Event-Based Job Triggering: Beyond just scaling pods, KEDA can schedule Kubernetes jobs based on events, ideal for tasks that don’t need constant running but might require significant resources intermittently.
- Specifying Custom Formulas: When defining multiple scalers in a ScaledObject, KEDA allows for personalized scaling rules by specifying a custom formula to evaluate the target value used to drive the autoscaling.
- Pausing Autoscaling via Annotations: KEDA enables pausing auto scaling at will using Kubernetes annotations, ensuring stability during maintenance or debugging sessions.
- Fallback: KEDA allows defining a number of replicas to fall back to if a scaler is in an error state, ensuring reliability.
- Fine Tuning Autoscaling with Telemetry: KEDA provides valuable insights through its telemetry capabilities, aiding in the refinement of autoscaling strategies.
- Kubernetes Events: Emitting events for KEDA CRDs aids in diagnosing and resolving scalability issues efficiently.
- Authentication Providers: Ensuring secure connections with external entities is crucial, and KEDA supports various authentication providers to cater to diverse needs.
The range of features KEDA offers is vast and warrants an in-depth exploration; for a comprehensive list, refer to the official documentation![]() .
.

Conclusion
In the ever-evolving landscape of cloud-native applications, adapting to dynamic workloads is a necessity. While Kubernetes provides native tools like HPA and VPA, their limitations become apparent in scenarios where applications demand responsiveness beyond CPU and RAM metrics.
KEDA not only overcomes these shortcomings but also offers a seamless and user-friendly interface for diverse autoscaling needs. Its ability to scale down to zero, triggering Kubernetes jobs, emit real-time events for diagnostics, and maintain secure connections through authentication providers, sets KEDA apart as a comprehensive solution. Moreover, setting up KEDA is simpler, reducing the typical hurdles users face with Kubernetes custom metrics.