KEDA vs HPA: Which Kubernetes Autoscaler Should You Use?
by Sharad Regoti
March 30, 2024
Introduction
If you are choosing between KEDA and HPA, the short answer is this: HPA is Kubernetes’ built-in autoscaler for resource and API-exposed metrics, while KEDA extends HPA for event-driven workloads, external systems, and scale to zero. If you only need CPU or memory based scaling, HPA may be enough. If you need queues, HTTP, Prometheus, OpenTelemetry, cloud services, or job-driven scaling, KEDA is usually the better fit.
KEDA does not replace HPA. It works with HPA and fills the gaps HPA leaves behind, especially when signals live outside the cluster or when workloads should scale from 0 to 1 instead of staying warm all the time.
This guide explains where HPA stops, where KEDA begins, and how to choose the right autoscaling model for each workload. If you need a primer first, start with what Kubernetes autoscaling means in practice.
Is KEDA and HPA the same?
To understand the differences, we first need to look at how HPA works.
Working of HPA
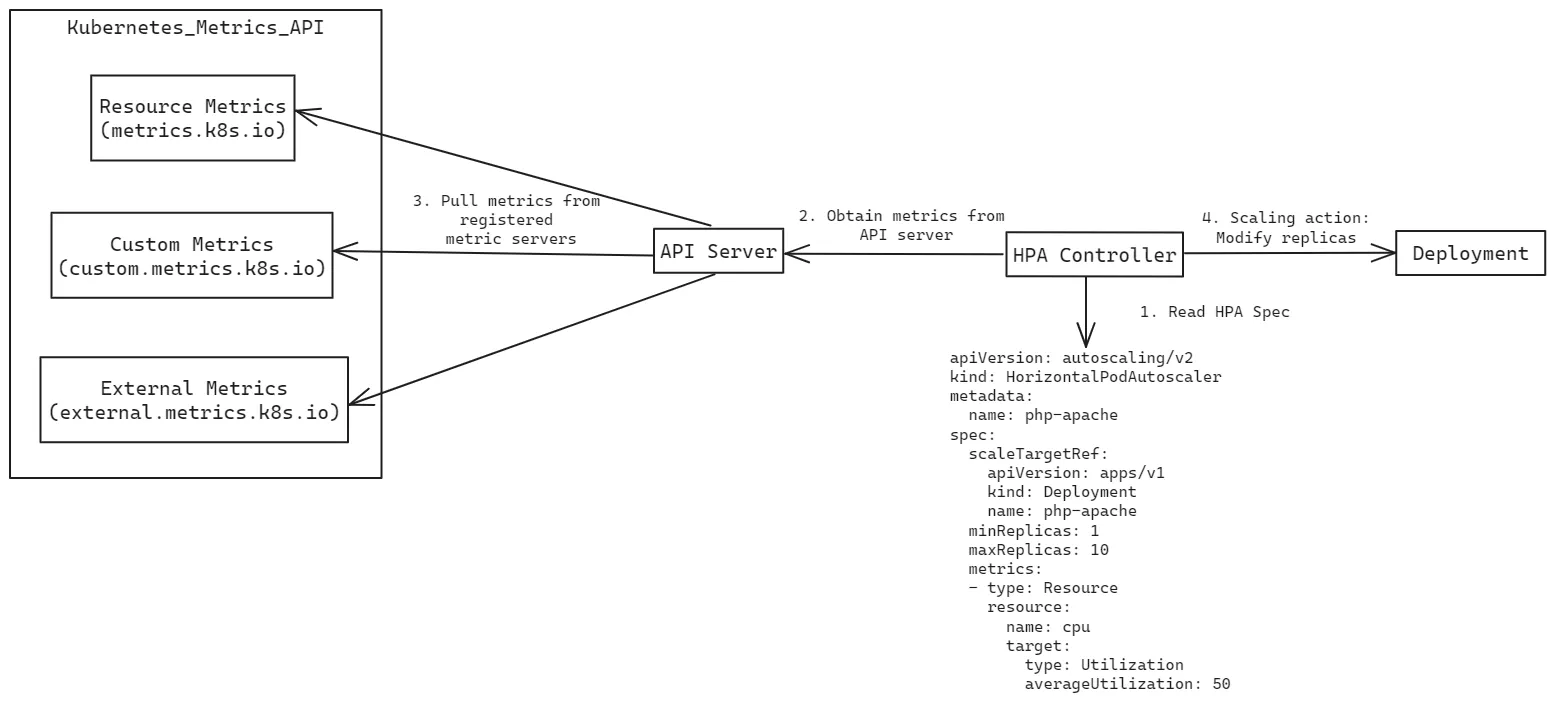
HPA (Horizontal Pod Autoscaler) consists of two main components:
-
Metrics from K8s Metrics API:
In Kubernetes there are three types of metrics APIs available:
-
Resource Metrics: Provided by the
metrics.k8s.ioAPI , this is generally served by the metrics-server.
, this is generally served by the metrics-server. -
Custom Metrics: Available through the
custom.metrics.k8s.ioAPI, these metrics are provided by metrics solution vendors such as Prometheus Adapter and AWS Cloudwatch Adapter.To know more about how KEDA compares to Prometheus adapter, refer this blog post.
-
External Metrics: Provided by the
external.metrics.k8s.ioAPI, these can be offered by the same custom metrics adapters mentioned above.
To ensure these metrics are accessible, you need to install the corresponding adapters or servers that register these services with the Kubernetes API server.
-
-
HPA Controller:
The Horizontal Pod Autoscaler (HPA) controller retrieves metrics from the Kubernetes API server using the APIs mentioned above.
It leverages these metrics, along with the HPA specification, to make scaling decisions. Based on these decisions, the HPA controller directly modifies the underlying deployment, adjusting the number of pod replicas to meet the current demand.
Autoscaling using HPA
apiVersion: apps/v1kind: Deploymentmetadata: name: php-apachespec: selector: matchLabels: run: php-apache template: metadata: labels: run: php-apache spec: containers: - name: php-apache image: registry.k8s.io/hpa-example ports: - containerPort: 80 resources: limits: cpu: 500m requests: cpu: 200m---apiVersion: autoscaling/v2kind: HorizontalPodAutoscalermetadata: name: php-apachespec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: # Type Resource configures HPA to fetch metrics from resource.metrics.k8s.io API - type: Resource resource: # This is the name of the metric to be searched in the resource.metrics.k8s.io API name: cpu target: type: Utilization averageUtilization: 50The above YAML defines a php-apache deployment with one container running the registry.k8s.io/hpa-example image.
The HorizontalPodAutoscaler (HPA) ****targets the php-apache deployment. Specifies the minimum and maximum number of replicas (pods) to scale between (1 to 10 replicas). Sets a scaling policy based on CPU utilization with the target CPU utilization set to 50%.
The type: Resource specified in the YAML, configures the controller to use resource.metrics.k8s.io API (provided by metrics-server![]() ) and
) and name: cpu is the metric name to be queried.
Flow and Feedback Cycle:
- Metrics Collection:
- The HPA controller periodically queries the Kubernetes API server for CPU utilization metrics of the
php-apachepods. - the Kubernetes API server gets this data from the metrics server, which is installed as an add-on.
- The HPA controller periodically queries the Kubernetes API server for CPU utilization metrics of the
- Decision Making:
- The HPA controller evaluates the current CPU utilization against the target average utilization (50% in this case).
- If the current utilization is higher or lower than the target, the HPA controller calculates the desired number of replicas to match the target utilization.
- Scaling Action:
- If a change in the number of replicas is needed, the HPA controller updates the
php-apachedeployment with the new desired replica count. - Kubernetes then scales the deployment up or down by creating or terminating pods to meet the new desired state.
- If a change in the number of replicas is needed, the HPA controller updates the
- Continuous Monitoring:
- This process is a closed-loop feedback cycle. The HPA controller continuously monitors the metrics, makes scaling decisions, and updates the deployment as needed to ensure the application meets the defined criteria.
HPA ensures that your application scales dynamically based on the observed load.
Autoscaling on Metrics other than CPU & RAM
As discussed above, HPA takes scaling decisions based on the metrics available from the Kubernetes metrics API.
In the previous example, HPA used the metrics from the metrics-server![]() . The metric server is maintained by the Kubernetes community and can only provide CPU & RAM information at Pod and Node levels.
. The metric server is maintained by the Kubernetes community and can only provide CPU & RAM information at Pod and Node levels.
If you want to scale based on metrics other than CPU & RAM (e.g RabbitMQ queue size) you can create a Custom Metrics Server![]() that implements the
that implements the external.metrics.k8s.io API to make the external metrics available to the Kubernetes API. Since HPA already supports external metrics API, you only have to configure HPA spec to use these external metrics.
The below YAML shows an example HPA which uses metrics from an External metrics API.
apiVersion: autoscaling/v2kind: HorizontalPodAutoscalermetadata: name: php-apachespec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: # Type External configures HPA to fetch metrics from external.metrics.k8s.io API - type: External external: metric: # This is the name of the metric to be searched in the external.metrics.k8s.io API name: rabbitmq-queue-length selector: matchLabels: app: rabbitmq target: type: AverageValue averageValue: 20However, implementing a custom metric server uncovers a series of complexities and challenges.
- Complex Implementation Details
- Cluster Restrictions and Conflicts
- Maintenance Overheads
To learn more about the difficulties of implementing custom adapters, you can refer this blog post,
Due to the design limitations of the metrics-server and the challenges of making external metrics available in Kubernetes, native autoscaling features often fall short. This is where KEDA steps in to fill the gap.
How KEDA Overcomes Kubernetes Autoscaling Limitations
KEDA enhances and extends the functionality of HPA by providing the following:
-
Interface for External Event Sources: KEDA allows you to configure external event sources that bring metrics into the Kubernetes API. These metrics can then be utilized by HPA for autoscaling.
-
Exclusive Autoscaling Features
- Scale Down to Zero: KEDA enables scaling down to zero replicas when there is no load, saving resources.
- Event-Based Job Triggering: KEDA can trigger Kubernetes jobs based on events from external sources.
- Specifying Custom Formulas: You can use custom formulas for more precise autoscaling decisions.
- Pausing Autoscaling via Annotations: KEDA allows pausing autoscaling through specific annotations.
- Fallback: KEDA provides fallback options in case the primary scaling mechanism fails.
- Fine Tuning Autoscaling with Telemetry: KEDA offers advanced telemetry options for fine-tuning autoscaling.
- Kubernetes Events: KEDA can scale applications based on Kubernetes events.
- Authentication Providers: KEDA supports various authentication providers for secure access to external metrics.
To know more about these features in detail, refer to this blog post.
The below table summarizes the difference between HPA and KEDA
| HPA | KEDA | |
|---|---|---|
| Scaling from 0 - 1 | Not Supported | Yes, KEDA takes care of scaling from 0 - 1 & 1 - 0 (e.g. scale down to zero). |
| Scaling from 1 - n | Yes | No, KEDA leverages HPA for 1 - n & n - 1. In this case, KEDA provides the metrics required for HPA to make scaling decisions. |
| Scaling Based on CPU & RAM | Yes, provided metrics are available from the Kubernetes metrics API | Yes, KEDA only provides metrics to Kubernetes API, actual scaling decision is taken by HPA. |
| Scaling Based on metrics other than CPU & RAM. | Yes, provided metrics are available from the Kubernetes metrics API | Yes, KEDA has created many scalers that, when configured, provide metrics to the Kubernetes API, but the actual scaling decision is taken by HPA. |
| Scaling Based on HTTP Metrics (e.g request rate) | No | Yes, KEDA has an HTTP addon that provides http metrics to Kubernetes API, but the actual scaling decision is taken by HPA. |
| Custom Event Scalers . | No | Yes, KEDA provides the ability to write custom scalers when the out-of-the-box scalers don’t meet the requirements. These custom scalers only provide metrics to the Kubernetes API, while the actual scaling decision is made by HPA. |
| Custom Formulas (Write custom mathematical expressions to evaluate scaling decisions) | No | Yes |
| Fallback (Ability to handle scenario where metrics are not available for scaling decision) | No | Yes |
| Fine Tuning Autoscaling with Telemetry | No | Yes |
| Event-Based Job Triggering | No | Yes |
Let’s dive deeper into KEDA working.
How KEDA works
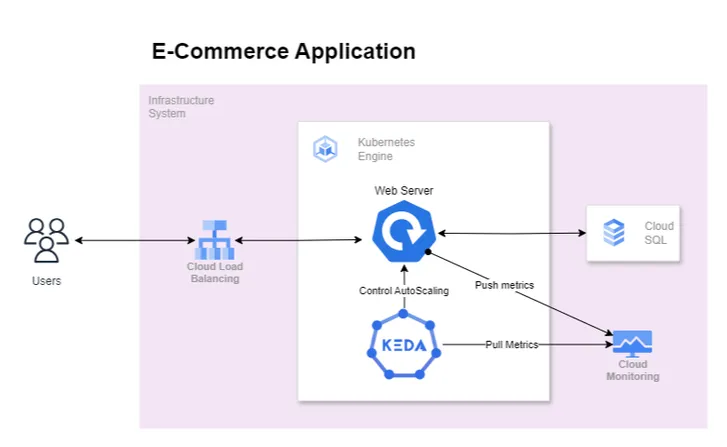
The diagram below shows how KEDA works in conjunction with the Kubernetes Horizontal Pod Autoscaler, external event sources, and Kubernetes’ etcd![]() data store:
data store:
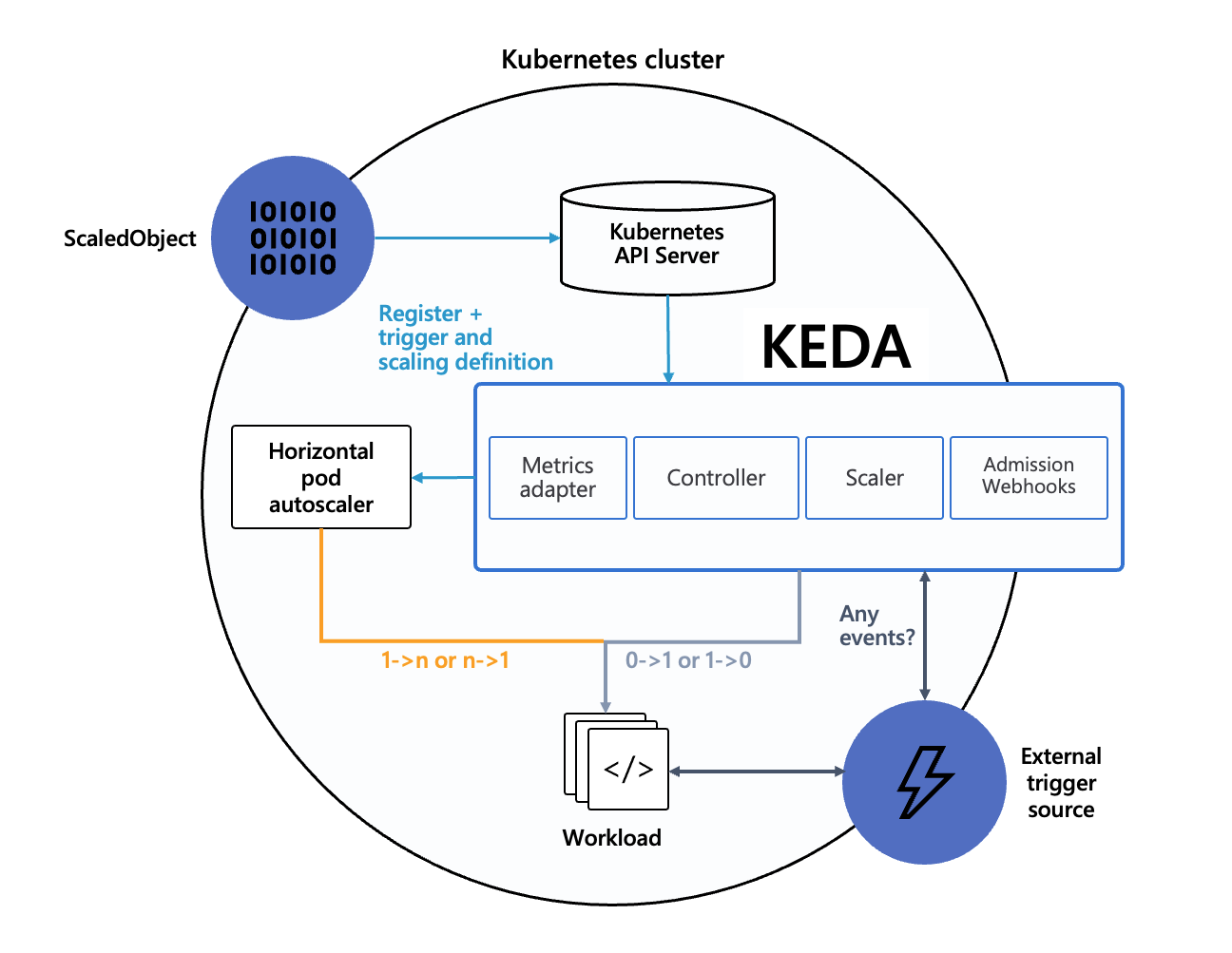
At its core, KEDA comprises of three key components:
-
KEDA Operator: A multifaceted entity comprising two essential components:
- Controller: Manages KEDA Custom Resource Definitions (CRDs) and activates/deactivates Kubernetes Deployments to scale to and from zero on no events.
- Scaler: Establishes connections to various event sources & fetches metrics.
This is one of the primary roles of the
keda-operatorcontainer that runs when you install KEDA. - Controller: Manages KEDA Custom Resource Definitions (CRDs) and activates/deactivates Kubernetes Deployments
-
Metrics Adapter/Server:
Implements the Kubernetes Custom Metrics API and acts as an “adapter” to translate metrics obtained by querying the KEDA operator (scaler) to a form that the Horizontal Pod Autoscaler can understand and consume to drive the autoscaling.
The metric serving is the primary role of the
keda-operator-metrics-apiservercontainer that runs when you install KEDA. -
Admission Webhooks: Automatically validate resource changes to prevent misconfiguration and enforce best practices using an admission controller.
To know more about KEDA architecture, refer the official docs![]() .
.
Autoscaling using KEDA
The YAML configuration below defines two Kubernetes resources: a Deployment for a php-apache application and a ScaledObject from KEDA to handle autoscaling based on RabbitMQ queue length.
apiVersion: apps/v1kind: Deploymentmetadata: name: php-apachespec: selector: matchLabels: run: php-apache template: metadata: labels: run: php-apache spec: containers: - name: php-apache image: registry.k8s.io/hpa-example ports: - containerPort: 80 resources: limits: cpu: 500m requests: cpu: 200m---apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata: name: rabbitmq-scaledobject namespace: defaultspec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicaCount: 0 maxReplicaCount: 10 triggers: - type: rabbitmq metadata: queueName: my-queue host: amqp://guest:guest@rabbitmq-host:5672/ queueLength: '20'The spec section of ScaledObject (a KEDA CRD) outlines how it should operate.
- scaleTargetRef: This section points to the deployment it will scale, in this case, the
php-apachedeployment. - minReplicaCount and maxReplicaCount: These fields define the minimum and maximum number of pod replicas. The deployment can scale down to 0 replicas (no pods) and up to 10 replicas based on load.
- triggers: This section defines the conditions that will trigger scaling actions.
- type: The type of trigger is
rabbitmq, meaning scaling actions are based on RabbitMQ metrics. - metadata: This section includes the details needed to connect to RabbitMQ and the specific scaling criteria:
- queueName: The name of the RabbitMQ queue to monitor,
my-queue. - host: The connection string for RabbitMQ,
amqp://guest:guest@rabbitmq-host:5672/. - queueLength: The queue length threshold for scaling, set to
20. If the queue length exceeds this value, the deployment will scale up.
- queueName: The name of the RabbitMQ queue to monitor,
- type: The type of trigger is
Flow and Feedback Cycle
When this configuration is applied, the following sequence of events takes place:
-
Initial Setup:
- Kubernetes creates the
php-apachedeployment, starting a pod with a single replica. - KEDA reads the ScaledObject specification and starts collecting metrics from RabbitMQ, making them available to HPA.
- KEDA also creates an HPA resource to control scaling from 1 to n and n to 1. Below is an example HPA spec created by KEDA:
apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata:name: keda-hpa-rabbitmq-scaledobjectnamespace: defaultspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10metrics:- type: Externalexternal:metric:name: rabbitmq-queue-lengthselector:matchLabels:scaledObjectName: rabbitmq-scaledobjecttarget:type: AverageValueaverageValue: 20 - Kubernetes creates the
-
KEDA in Action (Scaling From 0 to 1 and 1 to 0):
-
As ScaledObject is configured with minReplicaCount set to 0. If the queue length is below 20 and the current pod replica is 1, KEDA will scale down the application to zero after the cooldown period
. KEDA scales it back to 1 when the queue length exceeds 20. During this period, HPA continues to monitor the metrics. -
If minReplicaCount is set to greater than 1, HPA manages all scaling decisions.
-
-
HPA in Action (Scaling 1 to n and n to 1):
When the queue length exceeds 20 and the current replica count is 1, HPA scales the deployment up by creating more pods to handle the load. Conversely, it scales down the replicas when the queue length falls below 20.

Wrapping Up, KEDA vs HPA
KEDA is an extension of HPA, It does not replace HPA. It uses HPA under the hood to drive scaling action from 1 - n (by providing HPA with the required external metrics). Scaling from 0 - 1 is taken care of by KEDA, as HPA does not have this capability.
In addition to leveraging HPA for autoscaling, KEDA adds exclusive features not natively supported by HPA, enhancing the overall autoscaling experience.
KEDA’s additional features and support for external metrics make it a powerful tool for more flexible and dynamic autoscaling in Kubernetes environments. By extending the capabilities of HPA, KEDA ensures that your applications can scale effectively based on a wide range of metrics and events.