Kubernetes Vertical Autoscaling Without Restarts: In-Place Resize Explained
January 20, 2025
If a workload needs more CPU or memory per pod, horizontal scaling is not always the right answer. For stateful systems, heavy warm-up phases, or predictable startup spikes, vertical autoscaling can be the more accurate tool.
This guide explains how Kubernetes in-place resource resize works and how Kedify’s PodResourceProfiles make that capability practical for real workloads. For a complementary pattern, see fast vertical scaling for spiky workloads.
Basics
It is a good practice to specify resources for all Kubernetes pods. If no resources are specified, Kubernetes considers them to be unlimited. This can lead to a noisy neighbor scenario where one pod can consume a significant amount of CPU or, in the worst case, all node memory.
Kubernetes allows two ways of defining resources:
- requests - soft limit used by K8s scheduler when calculating the node assignment (bin packing problem)
- limits - hard limit that is also enforced by kernel (
cgroupsfor CPU andoomkillerfor memory)
Example:
image: busyboxresources: requests: memory: 64Mi cpu: 300m limits: memory: 256Mi cpu: 600mIn addition to the well-understood memory and cpu, both sections can contain also ephemeral-storage for managing local ephemeral storage or extended resources that can look like this:
nvidia.com/gpu: '1'For the purposes of this blog post, we will keep things simple and focus only on CPU and memory, neglecting other resources and the new DRA![]() (Dynamic Resource Allocation).
(Dynamic Resource Allocation).
Resource Updates
In an ideal world, your workload wouldn’t contain any memory leaks and would require a relatively constant amount of CPU and memory during its lifetime. However, the world is not perfect, and this is often not the case.
In case of memory leak, no amount of resources will be sufficient, as memory will grow until the container in the pod is killed. However, if the application has a predictable resource consumption profile, we can do better.
Until recently, updating requests and limits was treated as a change to the pod’s spec, resulting in a pod restart, forcing all containers to start from the beginning.
In general, adding more resources for a workload is referred to as vertical scaling and is suitable for certain types of workloads. Simply increasing the number of replicas without resolving synchronization logic may not enhance the overall performance of the distributed system. Consider a legacy monolithic application that hasn’t been broken into smaller microservices yet.
Other type of suitable use-case is the application that does some heavy lifting during its startup. Java or Python applications have to do a lot of bytecode bootstrapping, zip expanding, class loading, etc. Jobs are also strong candidates since they typically execute a sequence of tasks in a deterministic and predictable order.
Pod Resource Profiles
Kedify Agent has a built-in controller that can help with such use-cases. Since version v0.1.4, it also creates Custom Resource Definition for so called PodResourceProfiles shortly PRPs. The main idea of this Kubernetes
resource is to declaratively specify when a workload should receive a resource update. The timing here is relative to the workload’s start. In other words, it is possible to specify that only after, for example, 60 seconds of
the pod being ready should the resources be updated to lower values. This feature and all its possible knobs are well described in our documentation![]() .
.
Example:
apiVersion: keda.kedify.io/v1alpha1kind: PodResourceProfilemetadata: name: prp-prometheusspec: target: kind: deployment name: prometheus-server containerName: prometheus-server trigger: delay: 1m newResources: requests: memory: 500M cpu: 500mCreating such resource will make the Kedify Agent to update the resources of all pods pertaining to prometheus-server deployment. Namely for the container called prometheus-server. This is very useful,
because Prometheus server performs the WAL (Write Ahead Log) replay and require significantly more memory than during its normal (non-startup) phase.
Related Prometheus issues for this topic:
People often solve this issue by giving Prometheus much more resources than it really needs for its normal runtime and end up in a sub-optimal resource situation. With PRPs one can describe the required resource allocation in higher detail that better captures the workload’s resource needs.
API
This CRD-based API doesn’t break the immutable infrastructure nor the GitOps contract, because the controller doesn’t update the workload definition (Deployment, StatefulSet) but only makes the update to its pods that should be fungible and transient and shouldn’t be part of the declarative configuration.
The PodResourceProfile can also target the set of pods using a well known podSelector labels. In fact it’s the same internal type as Services in Kubernetes use. However, when using .spec.selector.matchLabels or
.spec.selector.matchExpressions it is mutually exclusive with using the .spec.target (which was used in the example above). Using an arbitrary label selector allows for smooth integrations also with other
Kubernetes tools/primitives such as Jobs, CronJobs, ArgoRollouts, Knative Services, KubeVela Applications, etc.
API Expressivity
This simple API allows for addressing a single change to a container in a fleet of pods, but it can be plugged in such a way as to achieve quite complex emergent behavior. The Kedify Agent supports also use-case where multiple PRP resources can target a single workload.
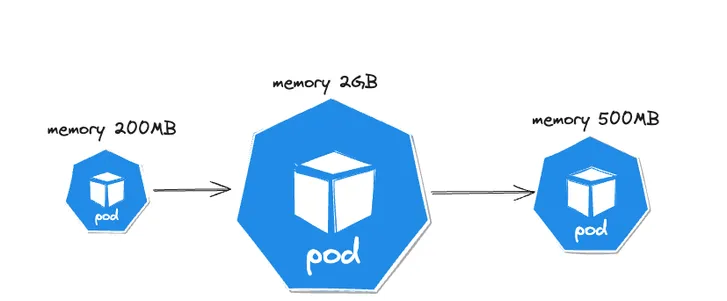
Imagine a following application’s memory profile:
This chart shows the memory profile of a demo application with four replicas. Each pod exhibits the following pattern:
- 30 seconds after startup: The memory requirement is around 500 MB.
- 90 seconds after startup: The memory requirement drops to 100 MB.
- Between 2 and 3 minutes: The application performs a memory-intensive task, causing memory consumption to skyrocket to 2.1 GB.
- 3.5 minutes after startup: The memory drops to 240 MB and stays there.
To match this curve using PodResourceProfile (PRP) API, we simply create one PRP for each step. At the very beginning, when the application requires 500 MB, we define this in the workload itself.
---# under pods containerSpec called 'main':resources: requests: memory: 500Mi limits: memory: 600MiapiVersion: keda.kedify.io/v1alpha1kind: PodResourceProfilemetadata: name: eshop-90sspec: target: kind: deployment name: eshop containerName: main trigger: delay: 90s newResources: requests: memory: 100M limits: memory: 150MapiVersion: keda.kedify.io/v1alpha1kind: PodResourceProfilemetadata: name: eshop-130sspec: target: kind: deployment name: eshop containerName: main trigger: delay: 130s newResources: requests: memory: 2G limits: memory: 2.3GapiVersion: keda.kedify.io/v1alpha1kind: PodResourceProfilemetadata: name: eshop-240sspec: target: kind: deployment name: eshop containerName: main trigger: delay: 4m newResources: requests: memory: 240M limits: memory: 300MThat should be it. The Kedify controller recognize what PRP is the next unapplied and applies them in a right order. Also if multiple PRPs match a single pod, one can override the default ordering (time) using
the priority field - .spec.priority

Conclusion
If the internal architecture of a workload isn’t inherently suitable for horizontal scaling out of the box. Its refactoring or rewriting into a microservice architecture is too expensive, or the initial bootstrapping
can’t be done using initContainers, you can leverage the Kubernetes In-place Resource Resize. Kedify supports this feature and provides a convenient CRD-driven API, allowing resource updates to be provided declaratively
in a gitops way.
We have demonstrated how multiple PodResourceProfiles can effectively model any resource consumption curve. There are numerous tools that can help you with right-sizing the requests and limits for your
application, Kedify has also this feature in the dashboard, however sometimes the resource needs are just a function of time and can be modeled upfront.
An interesting use case for this feature could be implementing a standby mode. For example, you could allocate 2 CPU cores to the application for the first hour, and then throttle it to just a fraction of a core for the remainder of its lifecycle. This could be particularly useful for running a test suite against the application and debugging it after the tests have completed.
Related Kedify resources
- Pod Resource Autoscaler for fast vertical scaling
- Shrink idle pods instead of scaling all the way to zero
- How vertical autoscaling fits into modern Kubernetes autoscaling
- Kedify product overview
We invite you to try out Kedify’s solutions and experience the benefits firsthand. For any questions or support, please contact us.