Work with HPA instead of fighting it
Kedify does not replace Kubernetes HPA. It adds control loops for workloads that need richer signals, faster reactions, or scale-to-zero behavior.
See where HPA fits
Thank you! We'll be in touch to schedule a meeting.
If you prefer, you can select a meeting time below:
Use one platform alongside HPA and Cluster Autoscaler to handle pod, HTTP, and event-driven scaling. Keep latency low, cut cost, and scale to zero when idle.
Please download your copy.
We help engineering and finance teams optimize costs, improve performance, and scale
effortlessly—across Kubernetes,
ML workloads, and event-driven systems.
In your demo, we’ll cover:
Search intent: Kubernetes autoscaler
When teams search for a Kubernetes autoscaler, they are often trying to map several layers at once: pod scaling with HPA, event-driven scaling with KEDA, node scaling with Cluster Autoscaler, and the operational glue needed to make those systems work well together. Kedify fits into that stack by improving workload-level autoscaling rather than replacing the rest of Kubernetes.
The practical decision is which autoscaler should react to which signal. Resource metrics, request rate, queue depth, Prometheus series, and forecasted demand should not all be forced through the same loop. Separating those paths is how teams reduce latency spikes, idle cost, and scaling noise.
Kedify does not replace Kubernetes HPA. It adds control loops for workloads that need richer signals, faster reactions, or scale-to-zero behavior.
See where HPA fitsQueues, external systems, and application metrics often describe demand better than raw CPU. That is where KEDA-backed autoscaling becomes the practical next step.
Review Prometheus autoscalingFor APIs and web workloads, request-aware autoscaling plus waiting and maintenance pages protect UX while still allowing aggressive idle cost reduction.
Read the scale-to-zero guidePlatform teams rarely run one autoscaler for one service. Kedify helps standardize autoscaling policy across clusters, teams, and mixed workload classes.
Estimate the ROIThink of Kedify as the layer that makes workload autoscaling more capable and more precise. HPA remains useful for standard resource-driven services. KEDA extends Kubernetes toward external and event-driven signals. Kedify then adds faster request-aware paths, better cold-start handling, and stronger multi-cluster operations for teams that need consistent behavior beyond one namespace or one cluster.
That model is especially useful if you already run a mix of synchronous APIs, background workers, and cost-sensitive workloads. It lets each workload follow the control loop it actually needs, instead of flattening everything into one generic autoscaler configuration.
Choose the right autoscaler based on signal source, workload type, and whether scale to zero matters.
Why adapter-heavy Prometheus autoscaling often pushes teams toward KEDA-based workflows.
A practical comparison for teams deciding between DIY KEDA setups and a broader autoscaling platform.
How Kedify fits alongside HPA, Cluster Autoscaler, and specialized scaling loops in production.
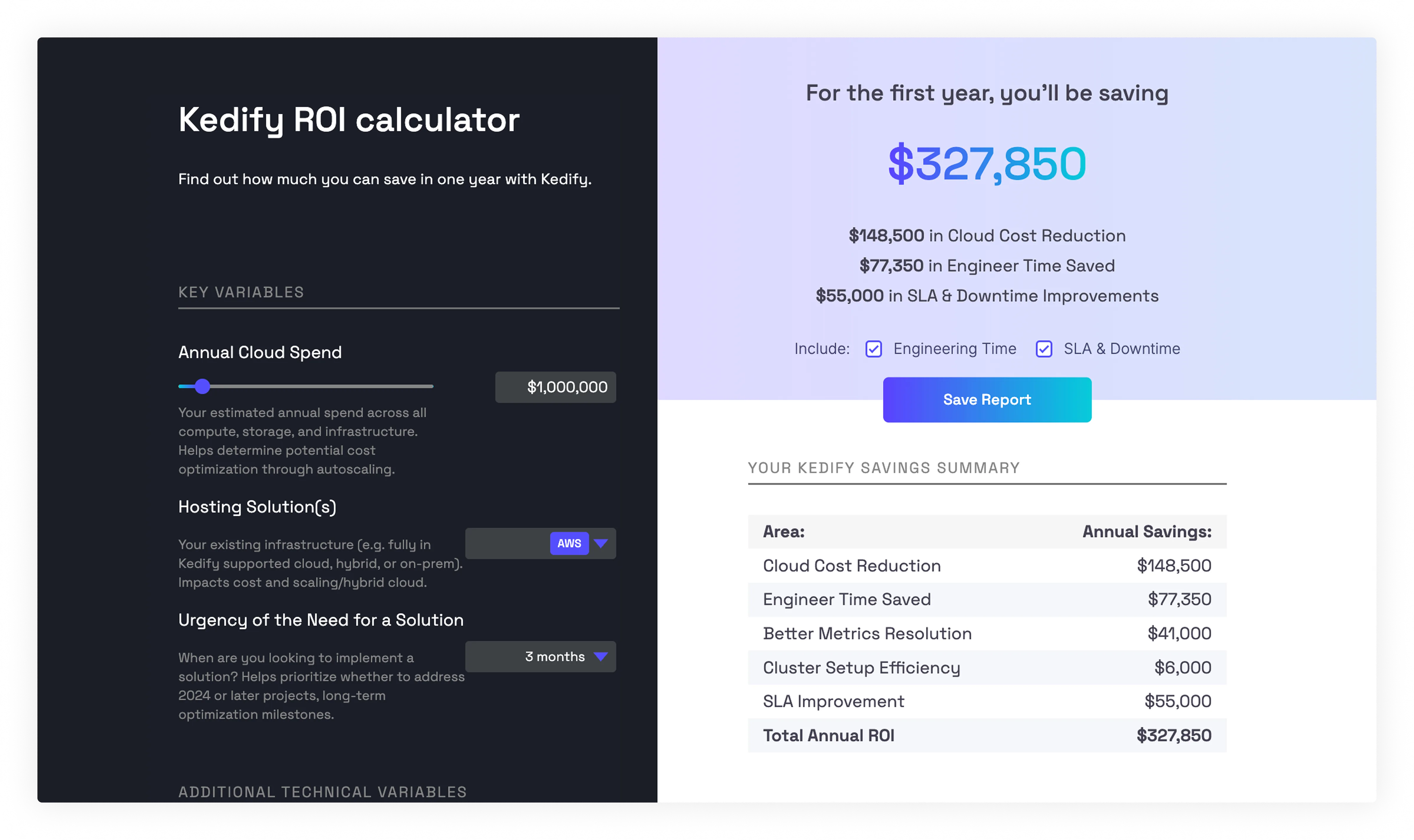
Estimate your potential savings in seconds with the Kedify ROI Calculator.
Launch ROI Calculator