Black Friday Is Over: Could Your Kubernetes Cluster Handle the Load?
December 02, 2024
Ah, Black Friday—the annual shopping frenzy that tests not just our wallets but also the resilience of our applications. Millions of users flock to online stores, streaming platforms, and ticketing systems, all expecting seamless experiences despite the overwhelming traffic.
For e-commerce platforms, it’s about ensuring carts don’t crash. For video streaming services, it’s about delivering uninterrupted playback to viewers. And for logistics systems, it’s about processing orders and tracking shipments in real-time without delays.
As the dust settles, it’s the perfect time to reflect:
Did our Kubernetes clusters gracefully handle the surge, or were they left gasping for air?
For businesses, Black Friday isn’t just another day; it’s a stress test of their infrastructure. Applications must seamlessly scale to meet unpredictable spikes in traffic, whether it’s handling a surge in HTTP requests, managing growing queues in messaging systems, or accommodating real-time analytics workloads.
But here’s the kicker: scaling isn’t as straightforward as cranking up CPU and memory. It’s about intelligently responding to various (sometimes contradictory) demands in real-time.
Beyond CPU and Memory: The Need for Smarter Autoscaling
Traditional solution on Kubernetes with Horizontal Pod Autoscaler (HPA) rely heavily on CPU and memory metrics. While these are important, they don’t tell the whole story. Imagine a scenario where your application is CPU-light but handles a massive number of requests or messages. Relying solely on CPU and memory would leave your autoscaling blind to the actual load.
The Pitfall of Overprovisioning
One straightforward solution might be to overprovision resources—allocate more CPU and memory than you think you’ll need. While this approach can handle spikes, it’s not cost-effective. You’re essentially paying for idle resources during non-peak times, which can significantly inflate your operational costs. Being cost-conscious is not just wise — it’s essential.
Enter KEDA: Scaling with Purpose
KEDA![]() steps in to fill this gap. It allows you to scale your applications based on a variety of metrics—over 70 scalers, to be precise. Whether it’s the
length of a message queue in RabbitMQ or Kafka, or custom metrics from Prometheus (read
this blog for details), KEDA provides the flexibility to scale based on what’s truly
important for your application.
steps in to fill this gap. It allows you to scale your applications based on a variety of metrics—over 70 scalers, to be precise. Whether it’s the
length of a message queue in RabbitMQ or Kafka, or custom metrics from Prometheus (read
this blog for details), KEDA provides the flexibility to scale based on what’s truly
important for your application.
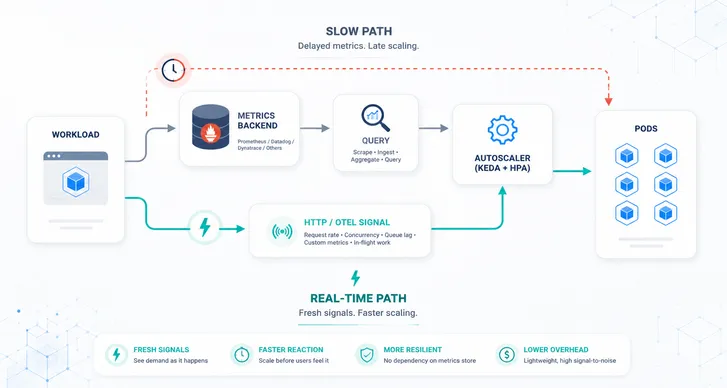
The Delay Dilemma with Monitoring Metrics
“Scaling based on monitoring solutions like Prometheus is a step up, but it comes with its own set of challenges. Metrics often arrive with delays due to scraping intervals and data processing times. In a Black Friday scenario, even a minute’s delay can lead to significant performance bottlenecks — and fewer items sold :-(
To tackle this, Kedify offers advanced KEDA scalers that enable real-time autoscaling:
OTEL Scaler: Immediate Insights for Instant Scaling
The OTEL Scaler integrates seamlessly with OpenTelemetry to provide immediate access to application metrics. By tapping directly into the OpenTelemetry data pipeline, this scaler minimizes delays associated with metric collection and processing. This ensures your scaling decisions are based on the most current data, allowing your applications to respond to load changes almost immediately.
Benefits of the OTEL Scaler:
- Reduced Latency: Eliminates the delay from metric scraping and processing.
- Custom Metrics: Scale based on any metric that OpenTelemetry collects.
- Flexibility: Works with various data types and sources.
Learn more in this detailed guide on OTEL scaler.
HTTP Scaler: Real-Time Scaling for Request-Driven Applications
For applications that are request-driven—such as web servers, APIs, or services using protocols like gRPC![]() and WebSockets
and WebSockets![]() — the HTTP Scaler is an ideal solution. Unlike traditional scalers that rely on indirect metrics, this scaler monitors incoming HTTP traffic in real-time. This direct approach allows your application to scale up or down immediately in response to traffic changes.
— the HTTP Scaler is an ideal solution. Unlike traditional scalers that rely on indirect metrics, this scaler monitors incoming HTTP traffic in real-time. This direct approach allows your application to scale up or down immediately in response to traffic changes.
Key Features of the HTTP Scaler:
- Real-Time Scaling: Instantaneous response to traffic spikes without delays.
- Protocol Support: Handles not just HTTP but also gRPC and WebSocket, making it versatile for modern microservices architectures.
- Scale to Zero: Automatically scales down to zero instances when there are no incoming requests, optimizing resource utilization and reducing costs.
- Resource Efficiency: By scaling based on actual request rates, you avoid overprovisioning and save on operational costs.
Learn more in this detailed guide on HTTP scaler.
The Domino Effect: Scaling Without Overloading Dependencies
Autoscaling isn’t just about your application pods. When you scale out, you increase the load on downstream services like databases. Without proper checks, you might end up overwhelming these critical components.
Mitigating Overload with Backpressure
Implementing backpressure mechanisms or connection throttling can help manage the load on downstream services. By controlling the rate of incoming requests or connections, you ensure that your databases and other services aren’t overwhelmed. However, it’s important to use these techniques carefully to avoid slowing down critical services too much.
Dynamic Resource Allocation
Some applications, especially legacy or resource-intensive ones, require more CPU and memory during startup than during normal operation. Allocating static resources leads to inefficiencies and can strain your cluster’s capacity.
Pod Resource Profiles![]() allow you to dynamically adjust resource requests and limits. This means you can allocate more
resources during startup and scale them down afterward, optimizing resource utilization and reducing unnecessary costs.
allow you to dynamically adjust resource requests and limits. This means you can allocate more
resources during startup and scale them down afterward, optimizing resource utilization and reducing unnecessary costs.
Anticipating Cluster Scaling Needs
Scaling pods is faster than scaling nodes. Kubernetes Cluster Autoscaler can take several minutes to provision new nodes, which might be too slow during peak traffic times. Predictive scaling strategies can help by anticipating the need for more nodes before the actual load hits.
By using advanced metrics and understanding traffic patterns, you can signal the Cluster Autoscaler ahead of time, reducing delays in node provisioning. Combining this with Kedify’s real-time pod scaling ensures that your applications and infrastructure scale smoothly together.

Conclusion
Black Friday may be over, but the insights gained are invaluable. By leveraging tools like KEDA you can build an autoscaling strategy that’s both responsive and cost-effective. It’s not just about handling the load—it’s about doing so efficiently, gracefully, and without breaking the bank.
Ready to take your autoscaling to the next level? Explore how Kedify can empower your Kubernetes clusters to meet any challenge head-on, while keeping costs under control.
We invite you to try out Kedify’s solutions and experience the benefits firsthand. For any questions or support, please contact us.