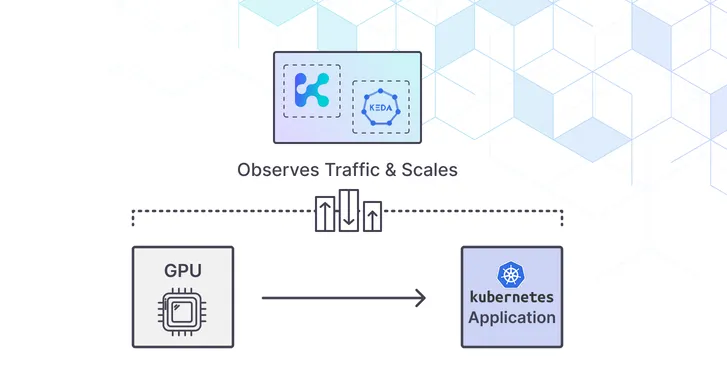
How to Autoscale GPU and LLM Workloads on Kubernetes
by Elieser Pereira
November 05, 2025
Scaling AI and ML Workloads Without Blowing Up Your Cluster
If you want to autoscale GPU and LLM inference workloads on Kubernetes, CPU-based scaling is not enough. These systems need traffic-aware routing, workload-aware metrics, and scaling behavior that protects both latency and GPU spend.
In this post, we’ll walk through why Kubernetes is a natural place for AI workloads, what challenges teams face when scaling, and how Kedify helps teams scale LLM inference efficiently using our HTTP scaler with vLLM. For proof from production workloads, see how Amigo scaled healthcare AI workloads with Kedify.
Why Run AI Workloads on Kubernetes?
If your organization is already using Kubernetes, it makes sense to host your AI/ML workloads there too. Here’s why:
-
Unified infrastructure - Running AI workloads on Kubernetes means one less environment to manage. Your platform team can apply existing tooling, policies, and automation without managing separate infrastructure for machine learning.
-
Cost control - Hosted AI services are often opaque and expensive. Running your own inference workloads in Kubernetes gives you visibility and control over GPU usage, making it easier to optimize spend and avoid vendor lock-in.
-
Security and compliance - Some AI workloads process sensitive or regulated data. Keeping these workloads in your own cluster allows tighter control over data residency, access policies, and audit requirements.
-
Flexibility - Kubernetes lets you run any AI framework or model that fits your needs. Whether you’re using PyTorch, TensorFlow, vLLM or llm-d, you’re not limited by vendor offerings.
Challenges and Risks of Scaling AI Workloads
While Kubernetes provides a solid foundation, scaling AI workloads comes with unique challenges:
-
Pricing - GPUs are powerful but expensive. Even small amounts of waste can balloon your infrastructure bill. Overprovisioning leads to idle resources, while underprovisioning causes latency spikes or failed requests.
-
Complexity - Deploying and scaling AI systems properly requires managing workloads with specific requirements that can be deployed by different tools in different ways. The industry lacks standardized approaches for LLM autoscaling.
-
Lack Of Standardization - The inference and serving landscape is ever-changing and can be overwhelming. Many teams rely on CPU-based autoscaling, but this doesn’t reflect GPU workload behavior, leading to inefficient scaling decisions.
vLLM for Inference at Scale
Real-time LLM inference is where autoscaling gets especially difficult. Models like LLaMA, Mistral, or GPTs consume significant memory and compute. Even with the many optimizations available you end up managing GPUs, traffic periodicity and user expectations for instant responses.
On the ever-growing landscape of LLM tools, the community seems to agree that vLLM solves many of the serving issues we have described so far. It’s a fast, open-source inference engine for LLMs that maximizes GPU utilization with techniques like PagedAttention, KV Cache aware routing, and Prefill/Decode Disaggregation.
But it doesn’t solve autoscaling by itself.
Kedify + vLLM: Autoscaling That Just Works
Kedify is a managed autoscaling layer built on KEDA, designed to scale modern workloads like LLM inference cleanly and efficiently.
Here’s what Kedify brings to the table when used with vLLM:
-
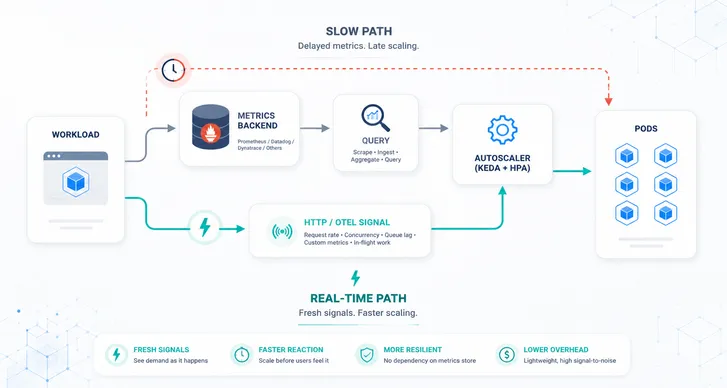
HTTP autoscaling based on actual demand - Our Kedify HTTP scaler integrates directly with vLLM’s request traffic, using metrics like in-flight requests and latency thresholds. It scales pods in and out based on real usage, not abstract CPU signals.
-
KV Cache and Prefix Aware - The Kedify HTTP scaler when deployed for inference workloads, deploys a configurable External Processor that can process inference requests and route them to maximize throughput based on signals like KV cache hit rate or forward traffic to instances that previously got a similar request. These techniques allow you to optimize GPU usage and are available out of the box on the Kedify HTTP scaler.
-
Latency and throughput awareness - You can define thresholds like “scale out if response latency exceeds 300ms for more than 10 seconds.” This prevents cold starts during traffic spikes and avoids over-scaling during quiet periods.
-
GPU cost optimization - By scaling precisely to load, you avoid running expensive GPU pods that aren’t doing useful work. Teams using Kedify have cut costs by 30 to 40 percent compared to static or CPU-based scaling.

Example: LLM Inference with Kedify + vLLM
Serving a model with vLLM can be done simply by running the vLLM production-stack project or can also be done with llm-d model-service charts for complex distributed inference setups.
In scenarios with vanilla vLLM or if using distributed inference with llm-d, the Kedify HTTP scaler offers an integration capable of routing traffic to your models and autoscaling out of the box.
Setting Up Kedify HTTP Scaler with vLLM
Here’s how to configure autoscaling for your LLM inference workloads:
One of the most interesting features in the Kedify HTTP scaler is the capacity to use an EndpointPicker (EPP).
In the cloud native inference and serving landscape, an Endpoint Picker or Inference Scheduler routes traffic to the vLLM instance that has the greatest chance to provide better and quicker answers.
This is possible because the Endpoint Picker is aware of vLLM instance status and shared cache when available. Internally, the EPP forwards requests to instances with the greatest possibility to have cache hits.
EPP considers variables like:
- Scorers
- Filters
- KV cache
- Prefill/Decode type instances
vLLM Deployment
In this scenario, there is no automation or autoscaling involved. For having autoscaling available you can use the Kedify HTTP scaler as shown in the following section.
vLLM + Kedify
A typical use case assumes that you have the Kedify agent, which ensures all KEDA resources are available in your cluster.
Please note that for advanced use cases, tools available in the landscape mostly require you to use Gateway API.
We know this can be a limitation for some companies still serving their workloads through Ingress.
Scaling vLLM without Gateway API
With the Kedify HTTP scaler, it is possible to have all the advanced functionalities provided by Endpoint Pickers while using Ingress controllers, without additional tuning on your workloads.
On top of the existing application configuration, you just need to define a ScaledObject marked with the InferencePool annotation and the Kedify HTTP scaler will automatically deploy and autowire the Kedify proxy.
Inference traffic is then processed by the Endpoint Picker and routed automatically.
The ScaledObject also provides scaling targets that help autoscale the vLLM deployment.
Example ScaledObject
kind: ScaledObjectapiVersion: keda.sh/v1alpha1metadata: name: inferencepool namespace: inferencepool-namespace annotations: http.kedify.io/envoy-inference-pool: | name: inferencepool
spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: vllm-deployment cooldownPeriod: 6 minReplicaCount: 1 maxReplicaCount: 10 fallback: failureThreshold: 2 replicas: 1 advanced: restoreToOriginalReplicaCount: true horizontalPodAutoscalerConfig: behavior: scaleDown: stabilizationWindowSeconds: 5 triggers: - type: kedify-http metadata: hosts: application.keda pathPrefixes: /v1 service: vllm-deployment-service port: '8000' scalingMetric: requestRate targetValue: '500' granularity: 1s window: 10s trafficAutowire: ingressFinal Thoughts
Running AI workloads in Kubernetes unlocks cost savings, flexibility, and unified infrastructure. This comes with extra management complexity and without the right autoscaling strategy, it’s easy to waste GPU hours or deliver a poor user experience.
Kedify with the HTTP scaler gives you a purpose-built solution for LLM inference scaling. It combines the flexibility of vLLM with the precision of workload-aware autoscaling and routing, so you can focus on building AI products without babysitting your cluster.
Related Kedify resources
- How Amigo scaled AI workloads in healthcare with Kedify
- AI inference autoscaling use case
- Predictive scaler overview
- KubeCon talk on autoscaling LLM workloads
Want to see Kedify in action?
Book a call with our team. We’ll show you how to get started scaling LLM workloads smarter and faster.