From Intent to Impact: Introducing The 2025 Kubernetes Autoscaling Playbook
by Kedify Team
October 22, 2025
From Intent to Impact: Introducing The 2025 Kubernetes Autoscaling Playbook
Written by Zbynek Roubalik, Founder & CTO at Kedify
Autoscaling used to mean “add replicas when CPU is hot.” In 2025, that’s not enough. Our new ebook, The 2025 Kubernetes Autoscaling Playbook, captures a decade of lessons from real production systems and turns them into patterns you can ship: intent-first signals, push-based telemetry, practical guardrails, GPU-aware decisions, and a clear path from reactive loops to predictive capacity.
Why We Wrote This Book
In the foreword, we describe the hard-won lessons that keep repeating across teams: (1) scale on intent, not utilization; (2) prefer push over scrape for decisions; (3) guard the downstream systems you’ll hammer once you scale. That perspective came from “pagers, postmortems, and the creeping realization that CPU is a terrible proxy for what users actually feel.” The book bottles the patterns that proved “boringly effective”.
Autoscaling, we argue, is bigger than a feature; it touches traffic, metrics, controllers, nodes, GPUs and money. Expect a practitioner’s guide with patterns, YAML, and checklists rather than a theory dump.
Who It’s For
-
Platform/SRE/Infra leaders standardizing on Kubernetes who need reliable, intent-driven scaling that protects shared databases and external services.
-
Application & API owners running HTTP/gRPC at scale who want p95-aware autoscaling without cold-start faceplants.
-
AI/ML teams operating GPU inference or pipelines and looking to reduce idle minutes while keeping “first token” times stable.
It’s organized into 13 concise chapters, each focused on what works today and how to adopt it incrementally.
The Goals (and How the Book Delivers)
-
Replace CPU heuristics with intent signals. For APIs, think RPS/concurrency and tail latency; for workers, backlog size/age; for inference, inflight + VRAM headroom.
-
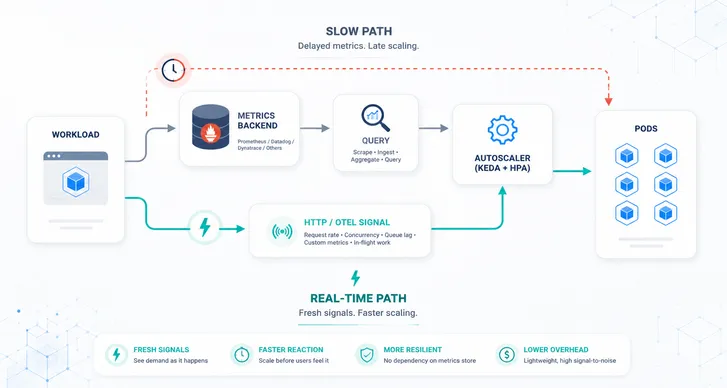
Cut the lag chain. The book quantifies why pull-only pipelines miss bursts (default Prometheus scrapes and the HPA loop add real seconds) and shows how push paths via OpenTelemetry fix it.
-
Scale fast & safely. You’ll find guardrails to prevent “autoscaling DDoS” of shared systems, plus waiting/maintenance pages to hide scale-from-zero.
-
Make costs visible. Strategies that make autoscaling legible to finance (so the wins survive budget season) are threaded through the guidance.

Highlights You Can Use Today
-
The Evolution: Where We Are Now
A clean timeline from HPA → VPA/resize → KEDA → Kedify, and why by 2025 the bottleneck is when you decide to scale, not whether nodes can arrive. -
Why CPU-Only Fails Modern SLOs
The book breaks down the lag chain (metrics → evaluation → HPA → warm-up) and shows how pull-only paths + default timings make you scale after the spike. It also explains why GPU minutes change the economics and make scale-to-zero and prewarm patterns essential. -
HTTP & gRPC Done Right
Concrete, copy-paste patterns: scale on RPS or concurrency, guard with p95/error rate, serve a waiting page on cold start, and cap aggregate replicas across services sharing a DB. It also includes gRPC gotchas (stream limits, slow-start) and Envoy circuit-breaking recommendations. -
KEDA Internals & Advanced Tuning
A practitioner’s map of activation (0↔1) vs replica math (1↔N), HPA behavior blocks, fallbacks (pin replicas when metrics fail), and Scaling Modifiers to compose signals (e.g., “gate on VRAM headroom”). -
Observability as a Control Surface
Push the signals you actually care about (inflight, p95, backlog) through OpenTelemetry for scaling decisions, keep Prometheus for breadth, and design the Collector with memory_limiter + batch so it won’t page you at 2 a.m. -
GPU-Aware Autoscaling for AI
Two proven patterns: (a) scale on intent and gate on GPU health (e.g., free VRAM) or (b) push a composite metric and scale on that (both paired with waiting pages and slow-start so the first user never pays the warm-up penalty). It also clarifies MIG vs time-slicing trade-offs. -
Cluster & Node Autoscaling That Actually Helps
When to choose Karpenter vs Cluster Autoscaler, how to keep a tiny overprovisioning buffer, and where in-place Pod resize quiets p95 without churn. -
Predictive Autoscaling: Blending, Not Replacing
Use short-horizon forecasts to prewarm just enough capacity, then let reactive scalers take over. Prefer quantiles, cap budgets, keep HPA stabilization windows long enough to avoid flapping, and measure value in SLO/cost deltas. -
Build vs Buy With Eyes Open
If you DIY, you own glue forever: edge proxying, waiting pages, group caps, hardened images, multi-cluster ops. The book lists common footguns (e.g., one KEDA per cluster, adapter pathing, mesh sidecars) so you don’t learn them during an incident.
How This Maps to Kedify (and Why We Built It)
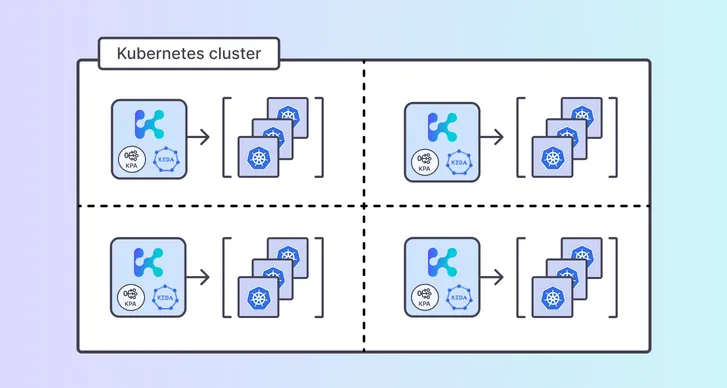
The playbook’s patterns are the ones Kedify operationalizes out of the box: an HTTP scaler that measures real traffic (including scale-to-zero with waiting pages), an OpenTelemetry scaler for push-first signals, ScalingGroups to protect shared backends, a multi-cluster dashboard, and hardened, enterprise-grade packaging around KEDA. There’s also support for dynamic vertical profiles to right-size pods alongside horizontal scaling.
What to Expect Next
The closing chapter previews where we’re taking the practice: predictive autoscaling gated by error budgets and cost caps, deeper GPU scheduling (MIG/time-slicing/topology), AI-assisted but bounded policies, multi-cluster scaling, budget-aware capacity orchestration, energy/carbon-aware placement, and new signals (eBPF) without turning the pipeline into a science project.
Get the Ebook
Download The 2025 Kubernetes Autoscaling Playbook - From Intent to Impact![]() and keep it beside your deploy script. Expect short chapters, ready-to-use YAML, diagrams that compare pull vs push paths, and practical checklists you can adopt in hours, not quarters.
and keep it beside your deploy script. Expect short chapters, ready-to-use YAML, diagrams that compare pull vs push paths, and practical checklists you can adopt in hours, not quarters.