Predictive Autoscaling for Kubernetes: Scale Before Traffic Spikes
October 23, 2025
Introduction
Traditional autoscaling reacts to what already happened. Predictive autoscaling tries to scale for what is about to happen. That difference matters for workloads with strong daily, weekly, or otherwise repeatable traffic patterns.
Kedify’s predictive scaler adds that foresight to Kubernetes autoscaling. By applying time series forecasting models like Prophet, Kedify can anticipate future workload changes and adjust scaling before the load hits your infrastructure. The result is smoother performance, fewer cold starts, and smarter resource utilization. If you want the reactive comparison first, start with resource-based vs proactive autoscaling delay.
From Reactive to Predictive Scaling
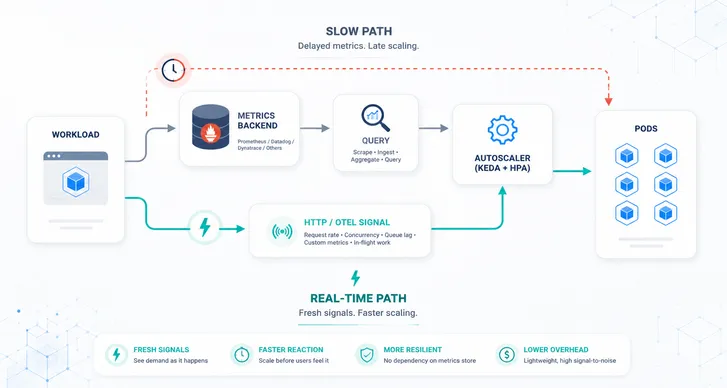
At the beginning there was HPA. HPA can react on CPU or memory utilization. With traditional KEDA scalers, you can plug in almost any metric and react faster than with classical HPA alone (HTTP requests, queue length, and so on). That works well for most workloads, but some patterns repeat predictably: daily peaks, weekly cycles, monthly jobs. Instead of chasing them, Kedify can learn them.
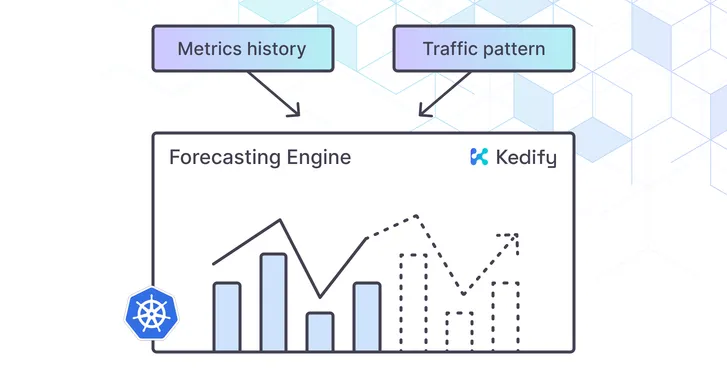
Once enough historical samples are collected, Kedify trains a forecasting model to predict metric values in the near future. These predictions feed directly into autoscaling decisions.
Common forecasting methods considered include:
- Moving average and exponential smoothing
- ARIMA
- Facebook Prophet
- LSTM neural networks
- Holt-Winters’ method
- etc.
Among them, Prophet stands out for its robustness, interpretability, and ability to handle seasonality without heavy tuning.
How the Predictive Model Works
The predictive system continuously collects metric data through Kedify’s integration with KEDA. Once enough data accumulates, the model enters a periodic training and evaluation cycle to maintain accuracy as patterns evolve.
During retraining:
- The dataset is split into a train set (90%) and a test set (10%).
- The model is trained on the train set and evaluated on the test set using the Mean Absolute Percentage Error (MAPE) metric.
- The acceptable MAPE threshold can be configured in the
kedify-predictivetrigger viamodelMapeThreshold. - If the model’s error exceeds the threshold, Kedify automatically returns a default value (also defined in the trigger) instead of an unreliable prediction.
This ensures the scaler remains stable and trustworthy, even if patterns change or data becomes noisy. We may use scaling modifiers to ignore the scaler if it returns the default value. Do not expect impossible, not all the data exhibit seasonal patterns and general ML rule of thumb: “garbage in, garbage out” also applies here.
In the visualization below, the light-blue shadow represents the model’s uncertainty bounds. When data collection was interrupted for several hours, the Prophet model still maintained a plausible fit. The widening confidence interval signals increasing uncertainty.
Explainability and Transparency
Although forecasting models can feel like black boxes, Kedify keeps them interpretable. Each model can be decomposed into seasonal and trend components (weekly, monthly, or custom) allowing visual inspection of whether the detected patterns make sense.
This decomposition helps operators trust (or challenge) predictions and fine-tune seasonality parameters as needed.

Try Kedify Predictive Autoscaling today
Experience proactive scaling with built-in forecasting.
Get StartedIntroducing the MetricPredictor CRD
Kedify introduces a new Custom Resource Definition: MetricPredictor. It represents the forecasting model and its lifecycle.
apiVersion: keda.kedify.io/v1alpha1kind: MetricPredictormetadata: name: rabbitspec: source: active: true keda: kind: scaledobject name: my-so triggerName: rabbit retention: 6mo # besides classical duration units 'y,mo,d' can also be used here model: type: Prophet defaultHorizon: 5m # if not overriden in trigger, 5min prediction will be used retrainInterval: 6h # the model will be retrained each 6 hours prophetConfig: holidays: countryCode: US # take the dates of holidays for us for this year and give the model freedom to escape the normal patterns during these days strength: 10 # reducing this parameter dampens holiday effects seasonality: yearly: 'true' weekly: 'true' daily: 'true' custom: name: twoHours period: 2h fourierOrder: 10 changepointPriorScale: 0.05Key points:
sourcedefines where metrics come from — either a liveScaledObjector a one-shot CSV for testing or bootstrapping the model with existing data.modeldefines the forecasting method (Prophet by default) and training cadence.- Kedify retrains models automatically on schedule.
Using Predictions in ScaledObjects
Once a MetricPredictor is created and trained, its predictions can be referenced directly in a ScaledObject trigger. This allows Kedify to scale based on forecasted metrics alongside real-time ones.
apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata: name: my-sospec: triggers: - name: rabbit type: rabbitmq metadata: queueName: tasks value: '1' - name: rabbitFromNearFuture type: kedify-predictive metadata: modelName: default*rabbit modelMapeThreshold: '40' highMapeDefaultReturnValue: '1' targetValue: '1' advanced: scalingModifiers: formula: '(rabbit + rabbitFromNearFuture)/2' target: '1' metricType: 'AverageValue'Benefits of Predictive Scaling
- Reduced reaction lag — the cluster scales before spikes hit.
- Improved UX — fewer cold starts and latency dips.
- Explainable models — operators can inspect trends and patterns.
- Robustness — automatic fallback to defaults when model confidence drops.
- Continuous learning — retraining keeps models aligned with current traffic.
- Stability -
modelMapeThresholdandhighMapeDefaultReturnValueprovide safety nets against poor model performance.
Implementation Notes & Future Extensions
This initial implementation supports Prophet, chosen for its balance of speed, accuracy, and explainability. Future releases will likely contain more ML techniques, giving operators more control over tradeoffs between complexity and precision.
Configuration flexibility such as retrainInterval, lookBackPeriod, and retention ensures Kedify fits both short-lived and long-term workloads.
Get Started
- See Predictive Scaler overview
- Explore Predictive Scaler documentation

- Please book demo to walk through a configuration tailored to your workloads.
Conclusion
Kedify’s predictive scaler marks a major step toward proactive autoscaling. By combining KEDA’s reactive event-driven scaling with machine learning forecasts, workloads can now adapt smoothly to what’s coming next, not just what already happened.