Keep KEDA, add the missing production paths
Kedify keeps KEDA at the center of the stack and adds the pieces teams usually need next: request-driven scaling, better cold-start handling, and tighter operator controls.
See the platform
Thank you! We'll be in touch to schedule a meeting.
If you prefer, you can select a meeting time below:
Keep your KEDA setup and add HTTP/gRPC autoscaling, predictive scaling, and scale-to-zero workflows without rebuilding your platform.
Please download your copy.
We help engineering and finance teams optimize costs, improve performance, and scale
effortlessly—across Kubernetes,
ML workloads, and event-driven systems.
In your demo, we’ll cover:
KEDA in production
KEDA is the right starting point for event-driven Kubernetes autoscaling, but it is rarely the whole production story. Teams usually still need faster request-driven loops, better scale-to-zero handling, and a clear answer for when HPA is enough versus when KEDA should take over.
This page is meant for that next layer. If you already run KEDA and want better coverage for HTTP workloads, predictive demand, or cross-cluster governance, Kedify extends the setup instead of asking you to replace it.
Kedify keeps KEDA at the center of the stack and adds the pieces teams usually need next: request-driven scaling, better cold-start handling, and tighter operator controls.
See the platformMove beyond queue depth and scrape-based loops when workloads need fast request-driven scaling, graceful cold-start behavior, and scale to zero for APIs and frontends.
Explore HTTP autoscalingAdd predictive and proactive control loops for workloads that follow recurring traffic patterns and cannot wait for CPU-based signals to catch up.
Read about predictive scalingUse one autoscaling surface for cost control, cross-cluster rollouts, and KEDA-based workloads that need more than a single-cluster control plane.
Compare Kedify with other optionsStart with intent, not tooling. If your workloads are driven by queues, streams, external APIs, or cloud services, KEDA is already a strong fit. The next validation step is whether you also need request-driven autoscaling, pre-warming for recurring peaks, or better fallback behavior when workloads are allowed to scale from zero.
For most platform teams, the practical question is not KEDA or Kedify. It is how to keep KEDA as the event-driven core while adding faster control loops and more operational guardrails where standard Kubernetes autoscaling falls short.
A direct comparison of event-driven KEDA workflows against standard Kubernetes HPA loops.
Why HTTP and gRPC workloads need request-aware scaling instead of relying on lagging resource metrics alone.
How to scale ahead of repeatable traffic spikes instead of reacting after SLOs are already at risk.
What breaks when teams bolt Prometheus onto HPA directly, and where KEDA simplifies the path.
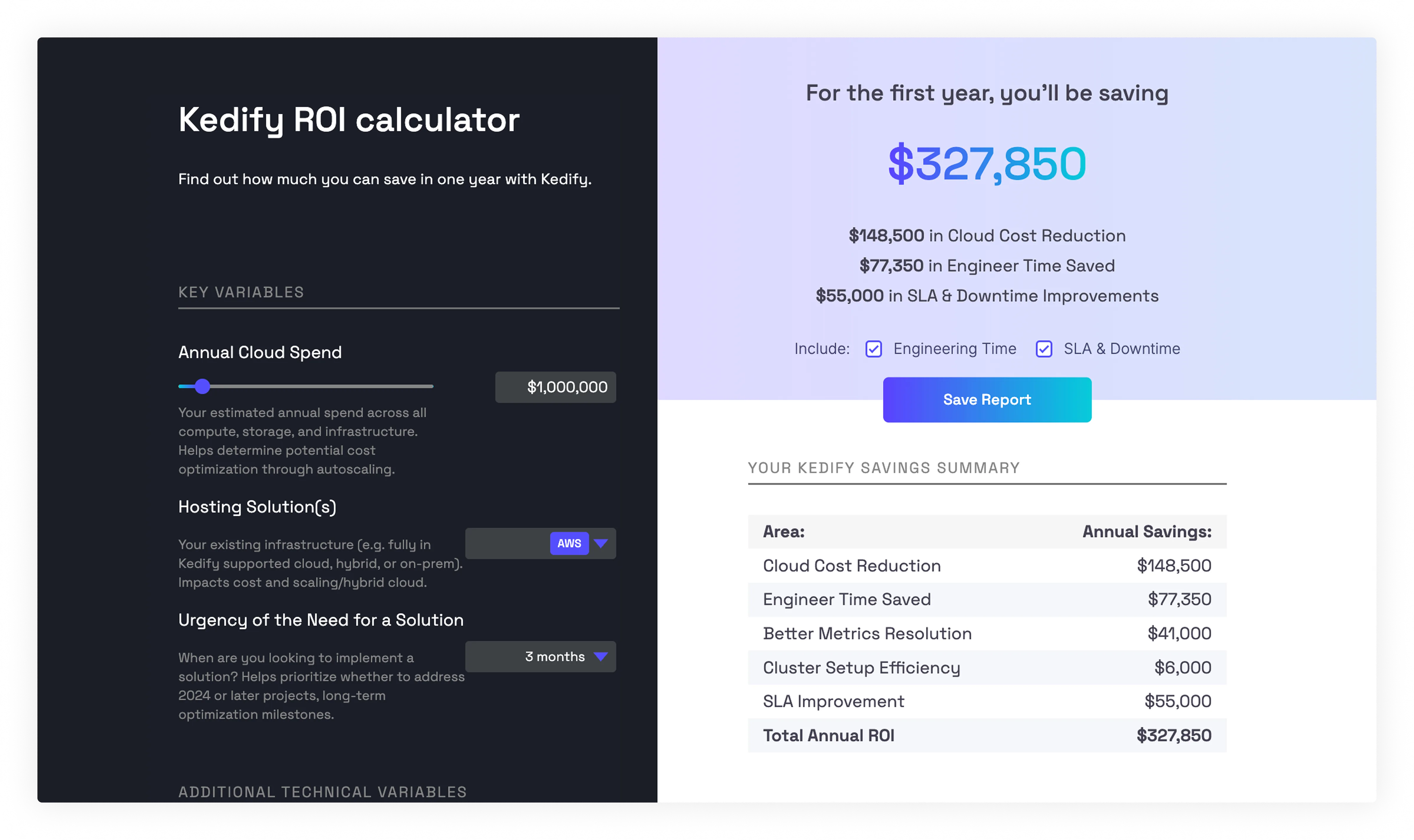
Estimate your potential savings in seconds with the Kedify ROI Calculator.
Launch ROI Calculator