Autoscaling AI Inference Workloads to Reduce Cost and Complexity
June 14, 2024
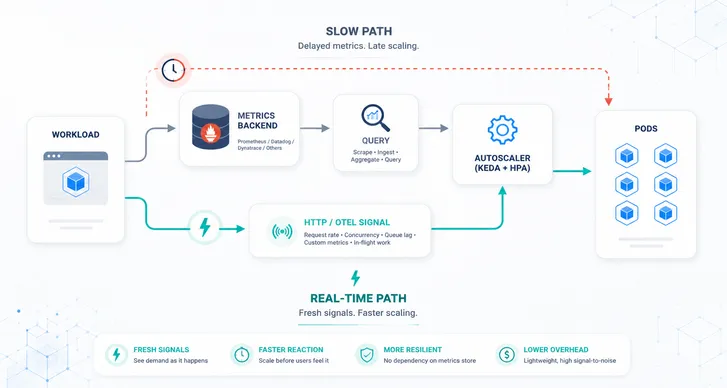
We often come across AI specific training and inference workloads implementing KEDA (or using a similar custom-built bespoke solution) in order to do event-driven autoscaling to reduce cloud costs and infrastructure complexity. Platform, SRE and engineering teams turn to event-driven autoscaling in these cases primarily to reduce the costs and complexity of their infrastructure because CPU and memory based scaling is not effective. But what are the specific details for how this type of event-driven autoscaling is to be implemented? What are the best practices for AI workload based autoscaling that optimizes for both cost and performance? In the case of AI workloads, overprovisioning and underprovisioning can be costly. We hope to review those here complete with an example use case using KEDA and Kedify.
A Real-World Anecdote
When OpenAI released ChatGPT, it quickly became clear that the high demand for the service required more robust scaling solutions. Initially, the infrastructure did not scale properly, leading to downtime (where the service was completely unavailable), as well as performance issues and bottlenecks. As the service grows, event-based autoscaling removes much of the guesswork from infrastructure planning as well as reduces the amount of manual intervention required.
Implementing AI Inference Autoscaling: A Stable Diffusion Example Application
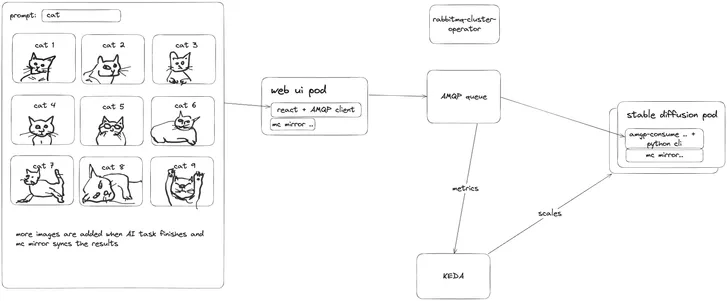
In this basic example, we will be using Kubernetes together with KEDA (Kubernetes Event-Driven Autoscaling) to autoscale a stable diffusion worker pods based on queued requests within a RabbitMQ queue. This set up monitors requests in a queue to determine whether or not the inference service provided by the stable diffusion pod requires scaling or not. An increase in requests in the queue will spawn additional Kubernetes Jobs (one job per each prompt request). Each Kubernetes Job then spawns a pod that consumes the task from the message queue and once is done with generating the image, it syncs the result to a shared object storage that’s also accessible from the web ui.
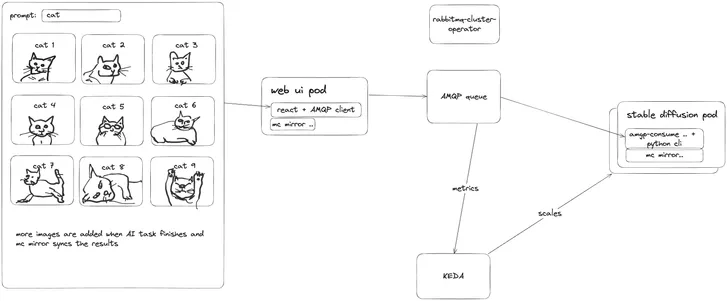
Diagram overview of this AI inference example application architecture.
For your convenience, we have also deployed this AI inference autoscaling demo dashboard![]() (no sign up required) using Kedify complete with an example web ui frontend
(no sign up required) using Kedify complete with an example web ui frontend![]() for triggering requests.
for triggering requests.
A Walkthrough of Key Components and Requirements
1. A Kubernetes cluster with a “web ui pod” (the frontend application for requesting stable diffusion inference via the RabbitMQ) and “stable diffusion pod” (inference service for executing generative ai requests)
2. Latest KEDA (Kubernetes Event-Driven Autoscaling) installed and configured using the following basic elements:
- ScaledJob named “stable-diff-job” within the “stable-diff” namespace
- max replica settings to limit the overall bandwidth
- jobTargetRef specifying the job spec (template) for each incoming task. It contains two pods, the main pod that triggers the neural network in feed-forward mode. This is a python application that operationalizes models from HuggingFace.co as well as a side-car container syncing the results
- triggers set to “1” RabbitMQ queue length
3. A frontend application “web ui pod” written in next.js framework exposed publicly using Ingress kedify.io![]()
The complete ScaledJob YAML![]() is below:
is below:
apiVersion: keda.sh/v1alpha1kind: TriggerAuthenticationmetadata: name: stable-diff-rabbitmq-connectionspec: secretTargetRef: - parameter: host name: stablediff-rabbitmq key: host---apiVersion: keda.sh/v1alpha1kind: ScaledJobmetadata: name: stable-diff-jobspec: jobTargetRef: template: spec: containers: - image: ghcr.io/kedify/stable-diffusion-worker name: stable-diffusion-worker imagePullPolicy: IfNotPresent resources: # uncomment if you want one GPU exclusively for this app, otherwise the GPU will be shared among many # limits: # nvidia.com/gpu: "1" requests: cpu: 400m memory: 1Gi volumeMounts: - name: shared-images mountPath: /app/results env: - name: AMQP_URL valueFrom: secretKeyRef: name: stablediff-rabbitmq key: host - name: DEVICE value: GPU - name: EXIT_AFTER_ONE_TASK value: '1' - image: minio/mc name: minio-sidecar env: - name: MINIO_USERNAME valueFrom: secretKeyRef: name: minio key: rootUser - name: MINIO_PASSWORD valueFrom: secretKeyRef: name: minio key: rootPassword resources: requests: cpu: 50m memory: 100Mi command: ['/bin/sh', '-c'] args: - | mc alias set shared http://minio:9000 $MINIO_USERNAME $MINIO_PASSWORD; mc admin info shared; echo "Minio configured, waiting for the result.." until [ -f /images/*.png ] && [ -f /images/*.json ]; do sleep 1; printf .; done echo -e "\nResults have been found: \n$(ls /images)\nSyncing.." mc mirror --exclude working /images shared/images;
volumeMounts: - name: shared-images mountPath: /images # if possible, spread the pods across all schedulable nodes affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: topologyKey: kubernetes.io/hostname labelSelector: matchLabels: app: stable-diffusion-worker volumes: - name: shared-images emptyDir: {} backoffLimit: 4 pollingInterval: 5 maxReplicaCount: 4 successfulJobsHistoryLimit: 0 rollout: strategy: default propagationPolicy: foreground
triggers: # https://keda.sh/docs/2.14/scalers/rabbitmq-queue/ - type: rabbitmq metadata: protocol: amqp queueName: tasks mode: QueueLength # QueueLength or MessageRate value: '1' activationValue: '0' authenticationRef: name: stable-diff-rabbitmq-connectionThis kubernetes resource instructs KEDA to start new Jobs based on the length of the AMQP queue called ‘tasks’. Once the message is consumed, the length of the queue decreases and the overall architecture converges on the optimal number of worker pods to request ratio. This can be further tuned by specifying field maxReplicaCount so that at one time there isn’t more than this number of worker replicas running.
The whole example is open-source and publicly available at kedify/examples github repository. It is also possible to deploy it locally to k3d or kind if you follow the steps in the readme file.

GPUs
In order for GPUs to be consumable by applications running in pods, they need to be first exposed by device plugin. Also drivers and CUDA need to be pre-installed on the kubernetes node. This step can be different for each cloud provider, but most of the time it’s delivered as a DaemonSet that has an init container or it spawns a Job for each Kubernetes node. It also does a GPU discovery on that node and is smart enough to skip the initialization for non-GPU nodes or nodes that does not expose any hardware accelerator like TPU. Part of this discovery process is also marking the Node with a label that can be later used for pod scheduling.
In our case we are using nvidia gpu and their proprietary technology called MPS that allows sharing GPU device among multiple workloads using the time slicing however if workloads requires whole GPU, this can be achieved by specifying the resources in its pod spec section namely nvidia.com/gpu: "1" see the code![]() .
.
Scale Down to and Up From Zero
Using KEDA, and Kedify for insights, and its ability to scale workloads to zero replicas if there is no incoming traffic, you can also utilize the cluster autoscaler or Karpenter that will scale down also the unused GPU nodes. In practice this means that your Kubernetes cluster consists of nodes that are CPU only and nodes that have GPUs and are appropriately marked with such label. Then if the workload requires to run on the GPU, it has a label selector on it. In case there is no such a node present in the cluster, Karpenter can create one. This approach suffers from a cold start, because now we have to bootstrap also the node and let the device plugin do its job, nonetheless to some degree this can be mitigated by baking the drivers or even container images into the image for the k8s node (be it AMI for AWS or ISO/OVA for Cluster API).
Key Benefits of Event-based Autoscaling AI Inference
- Cost Reduction: Autoscaling helps in reducing cloud costs by adjusting resources based on demand. This is especially true if scale down to zero is possible.
- Infrastructure Simplification: KEDA-based autoscaling reduces the complexity of managing infrastructure through standard CRDs and limited customization.
- Optimized Performance: Ensures that resources are efficiently utilized, maintaining optimal performance.
Conclusion
Event-driven autoscaling with solutions like KEDA can significantly reduce cloud costs and infrastructure complexity for AI workloads by optimizing resource allocation and minimizing inefficiencies. To explore best practices and see a real-world example, check out our AI inference autoscaling demo dashboard![]() and example web UI frontend
and example web UI frontend![]() . We would love to hear your
thoughts and experiences, please send us your feedback!
. We would love to hear your
thoughts and experiences, please send us your feedback!