Use HPA where resource signals are enough
CPU and memory-based HPA still fits steady workloads, but most platform teams eventually need richer signals and faster reactions than resource metrics can provide.
Review HPA guidance
Thank you! We'll be in touch to schedule a meeting.
If you prefer, you can select a meeting time below:
Coordinate HPA, event-driven triggers, HTTP workloads, jobs, and GPUs in one platform, with support for scale to zero and cold-start control.
Please download your copy.
We help engineering and finance teams optimize costs, improve performance, and scale
effortlessly—across Kubernetes,
ML workloads, and event-driven systems.
In your demo, we’ll cover:
Search intent: Kubernetes autoscaling
Teams searching for Kubernetes autoscaling usually need more than one answer. Some workloads scale well from HPA. Others need KEDA for external metrics, HTTP-aware loops for APIs, or faster signals than CPU and memory can provide. That is why the right model depends on workload shape, latency tolerance, and how much idle cost you are willing to carry.
Kedify helps platform teams combine those models into one operating surface. You can keep the standard Kubernetes primitives, add KEDA where event-driven behavior fits, and then extend into scale-to-zero, GPU workloads, and predictive scaling without forcing every service into the same loop.
CPU and memory-based HPA still fits steady workloads, but most platform teams eventually need richer signals and faster reactions than resource metrics can provide.
Review HPA guidanceKEDA extends Kubernetes autoscaling to queues, external systems, Prometheus, cloud metrics, and other signals that sit outside default HPA control loops.
Explore KEDA topicsUser-facing workloads need request-aware scaling, waiting pages, and fallback behavior that protect latency while still cutting idle cost.
See scale-to-zero patternsModern Kubernetes autoscaling goes beyond pods per CPU percentage. AI inference, proactive forecasts, and in-place resize all need dedicated control loops.
See broader platform coverageThe most common breakpoints are predictable: short traffic spikes, queue-driven services, Prometheus adapters that add more moving parts than value, and user-facing workloads that should scale to zero without serving a blank screen during cold starts. Those are the places where KEDA, HTTP autoscaling, and vertical autoscaling stop being nice-to-have additions and become the practical fix.
If you are planning an autoscaling architecture refresh, validate the workload classes first: background jobs, synchronous APIs, batch peaks, and GPU inference each need different signals and failure handling. Treating them all as plain HPA targets is what creates the lag and cost problems most teams are trying to escape.
A practical map from HPA to KEDA, real-time signals, and modern autoscaling control loops.
Why resource-based autoscaling is delayed by design and what faster control signals change.
How in-place resize changes Kubernetes capacity planning for bursty workloads.
Where request-aware routing and cost control matter for AI workloads on Kubernetes.
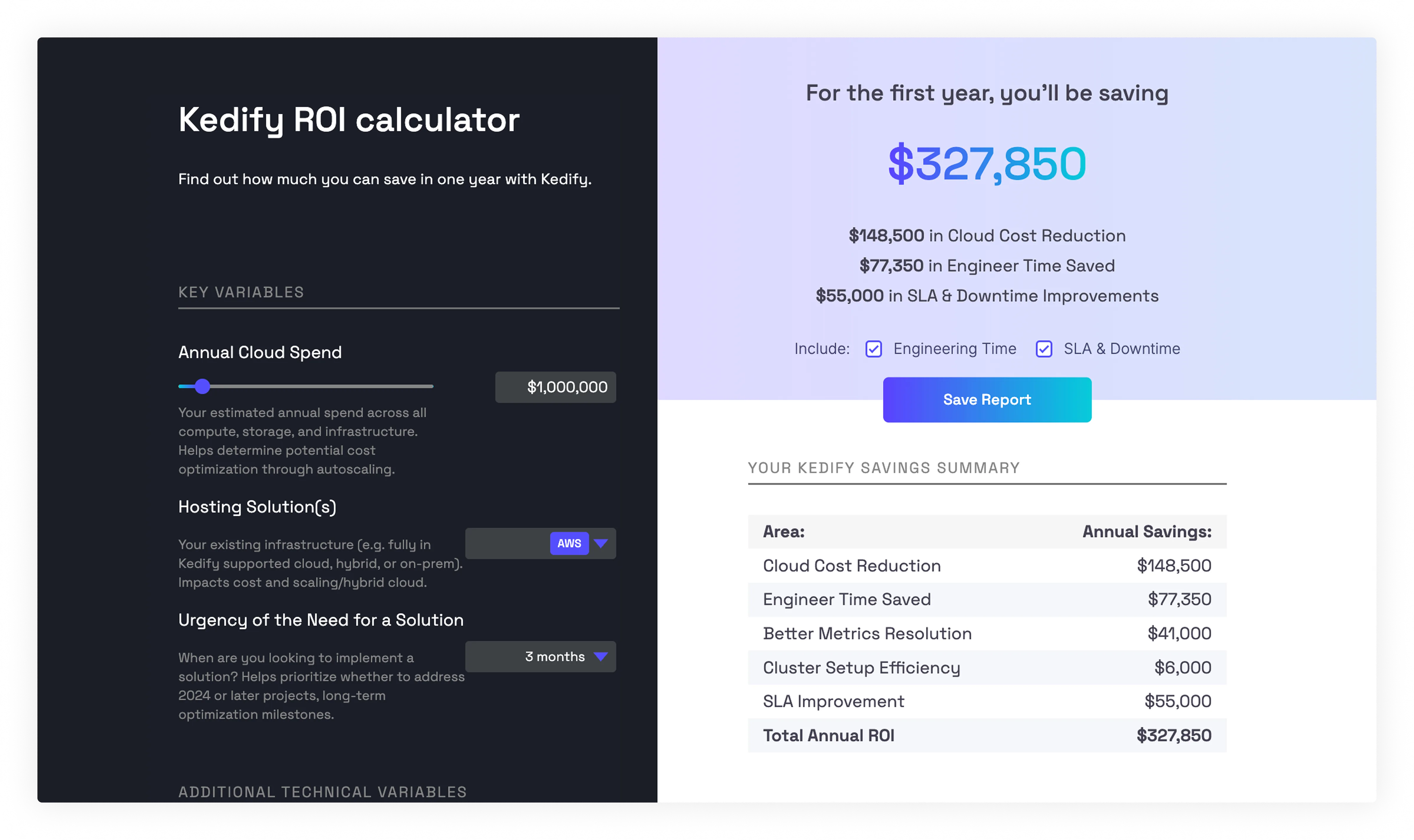
Estimate your potential savings in seconds with the Kedify ROI Calculator.
Launch ROI Calculator