Shrink Pods When Traffic Sleeps
September 09, 2025
Introduction
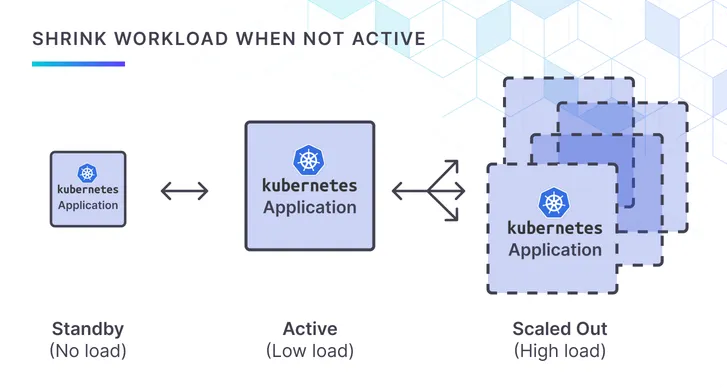
Most conversations about “scaling to zero” focus on replicas: spin every Pod down when demand drops, spin them back up later. That’s great if your app can cold-start in milliseconds. But what if you still need a single instance alive (think health-checks, long-lived connections, or stubborn frameworks) yet you don’t want it hogging 250 MB of RAM while users are away?
Vertical shrinking is the missing half of the puzzle: keep the Pod running, just ask the kernel for less. With Kedify you can now do exactly that by combining two building blocks you already know:
- ScaledObject: drives horizontal scaling based on real-time events.
- PodResourceProfile (PRP): performs in-place CPU / memory right-sizing whenever a trigger says so (see our previous post on PRP).
Starting today, .spec.target.kind: "scaledobject" binds the two together, letting a PRP react to a ScaledObject’s activated / deactivated lifecycle. The result: your last replica sips resources when idle and bulks up the moment traffic crosses your activation threshold—all without a restart.
Quick Recap: ScaledObject States
When does a ScaledObject change state?
- deactivated: event rate <
targetValuefor the configured cooldown period - activated: event rate ≥
targetValue(10 req/s in the example below)
These state flips are now first-class PRP triggers.
Hands-On Example: “nginx-standby” vs “nginx-active”
apiVersion: keda.kedify.io/v1alpha1kind: PodResourceProfilemetadata: name: nginx-activespec: target: # <-- bind to ScaledObject instead of Deployment kind: scaledobject name: nginx containerName: nginx trigger: after: activated delay: 0s # apply immediately on activation newResources: requests: memory: 250M---apiVersion: keda.kedify.io/v1alpha1kind: PodResourceProfilemetadata: name: nginx-standbyspec: target: kind: scaledobject name: nginx containerName: nginx trigger: after: deactivated delay: 10s # wait 10 s before shrinking newResources: requests: memory: 30M---apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata: name: nginxspec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: nginx minReplicaCount: 1 maxReplicaCount: 8 triggers: - type: kedify-http metadata: hosts: www.my-app.com service: http-demo-service port: '8080' scalingMetric: requestRate targetValue: '10'What Happens in Practice?
| Phase | Requests/sec | Active replicas | Memory per Pod |
|---|---|---|---|
| Quiet time | < 10 | 1 (min) | 30 MB (thanks to nginx-standby) |
| Surge | ≥ 10 | up to 8 | first Pod expands to 250 MB instantly via in-place resize; new Pods inherit normal resource spec |
| Cool-down | back < 10 | scales back to 1 | after 10 s the lone survivor shrinks to 30 MB again |
No restarts, no cold-start latency, just smarter utilisation.
Why 220 MB Matters (and Adds Up)
- Higher bin-packing density: the kube-scheduler can co-locate more idle services per node.
- Smoother Karpenter consolidations: once the “fat” idle Pods slim down, empty nodes are freed faster, driving real cloud savings.
- Zero traffic? Still fast: keeping one tiny Pod warm avoids the 3-5 second TLS handshake + framework boot you’d hit with pure scale-to-zero.
API Details & Gotchas
selectorandtargetare mutually exclusive.- PRP may point to either a label selector or an explicit target object (Deployment, StatefulSet, DaemonSet, ScaledObject).
- Triggers allowed when
kindis set toscaledobjectare onlyactivatedanddeactivated. - PRP and workload must reside in the same namespace (the controller doesn’t cross them).
- Underneath, Kedify uses Kubernetes in-place resource resize, so your cluster needs that feature-gate enabled (on by default in K8s ≥ 1.33).
Seeing It Live
We recorded a short terminal cast that shows kubectl top pod in real time while bombing the nginx endpoint. Watch RAM drop to 30 MB, then shoot back up the instant hey hits 10 RPS:
Where Does This Fit in Kedify’s Bigger Picture?
- HTTP Scaler Waiting Pages handle UX during cold starts.
- ScalingGroups prevent noisy neighbours from overrunning shared infra.
- PodResourceProfile + ScaledObject closes the loop by right-sizing the pod that must stay alive.
Together they give you a continuum of options. From zero replicas to one tiny container up to dozens of beefy workers, all driven by the real-world signals your application emits.

Ready to Try?
- Upgrade to the latest Kedify Agent (>= v0.2.17 for PRP-ScaledObject support).
- Make sure the PRP feature is turned on and based on this setting your target workload has annotated pods.
- Enable the
InPlacePodVerticalScalingfeature-gate on your cluster if it’s not already on. - Create your first
-standby / -activepair and watch your requested memory plummet.
Related Docs
-
PodResourceProfiles

-
How-to: PRP Shrink Pod Instead of Scale-to-Zero
- Our blog on Kubernetes Vertical Autoscaling with PRP
Built by the core maintainers of KEDA. Battle-tested with real workloads.